x86汇编语言(第2版):从实模式到保护模式
Chap1:十六进制计数法¶
二进制到十进制的转换¶
二进制和十进制都是进位计数法。 进位计数法的一个特点是,符号的值和它在这个数中所处的位置有关。比如,十进制数356,数字6处在个位上,所以是“6个”;5处在十位上,所以是“50”;3处在百位上,所以是“300”,即:
百位3、十位5、个位6=3×102+5×101+6×100
这就是说,由于所处的位置不同,每个数位都有一个不同的放大倍数,这称为“权”。每个数位的权是这样计算的(这里仅讨论整数):从右往左开始,以基数为底,指数从0开始递增的幂。正如上面的公式所清楚表明的那样,“6”在最右边,所以它的权是以10为底、指数为0的幂100;而3呢,它的权则是以10为底、指数为2的幂102。
上面的算式是把十进制数“翻译”成十进制数。从十进制数又算回到十进制数,这看起来有些可笑,注意这个公式是可以推广的,可以用它来将二进制数转换成十进制数。
比如一个二进制数10110001,它的基数是2,所以要这样来计算与它等值的十进制数:
在上面的公式里,10110001B里的“B”表示这是一个二进制数,“D”则表示177是一个十进制数。“B”和“D”分别是英语单词Binary和Decimal的首字母,这两个单词分别表示二进位和十进位的意思。
十进制到二进制的转换¶
为了将一个十进制数转换成二进制数,可以采用将它不停地除以二进制的基数2,直到商为0,然后将每一步得到的余数串起来即可。如图所示,如果要将十进制数26转换成二进制数11010,那么可采用如下方法:

- 第1步,将26除以2,商为13,余数为0;
- 第2步,用13除以2,商为6,余数为1;
-
第3步,用6除以2,商为3,余数为0;
-
第4步,用3除以2,商为1,余数为1;
- 第5步,用1除以2,商为0,余数为1,结束。
然后,从下往上,将每一步得到的余数串起来,从左往右书写,就是我们所要转换的二进制数。
十六进制到十进制的转换¶
要把一个十六进制数转换成我们熟悉的十进制数,可以采用和前面一样的方法。只不过,在计算各个数位的权时,幂的底数是16。将十六进制数125转换成十进制数的方法如下:
在上式中,125后面的“H”用于表明这是一个十六进制数,它是英语单词Hexadecimal的首字母,这个单词的意思是十六进制。
十进制到十六进制的转换¶
相应地,要把一个十进制数转换成十六进制数,则可以采取不停地除以16并取其余数的策略。

- 第1次,将293除以16,商为18,余5;
- 第2次,用18除以16,商为1,余2;
- 第3次,再用1除以16,商为0,余1,结束。
然后,从下往上,将每次的余数1、2、5列出来,得到125,这就是所要的结果。
Chap2: 计算机和汇编语言¶
处理器¶
1947年,美国贝尔实验室的肖克利和同事们一起发明了晶体管。1958年,也许是受够了在一大堆晶体管里连接那些杂乱无章的导线,另一个美国人杰克·基尔比发明了集成电路。接着,1971年,在为日本人设计计算器过程中,INTEL的弗德里科·法金灵机一动,他想,能不能把运算功能和控制功能集成到一起,设计一款可以自动取指令并执行指令的芯片呢?于是他发明了第一款处理器INTEL 4004,如图所示:

紧接着,INTEL又推出了8088和划时代的产品8086。4004是4位的处理器,8008是8位的处理器,而8086是16位的处理器。
8086是一款划时代的产品,应用非常广泛。虽然INTEL的处理器越来越先进,但它的 x86系列一直保持对8086的兼容性 。
在8086之后,INTEL又生产了80286和80386。80386又是一款划时代的产品,深刻地影响了后续的处理器设计。
处理器的位数是什么意思呢?
4位的处理器拥有4位的寄存器和算术逻辑部件;8位的处理器拥有8位的寄存器和算术逻辑部件;16位的处理器拥有16位的寄存器和算术逻辑部件;32位的处理器拥有32位的寄存器和算术逻辑部件;64位的处理器拥有64位的寄存器和算术逻辑部件。可以肯定的是,位数越多,寄存器就可以保存更大的数字,算术逻辑部件就可以在单次计算中使用更大的数字并产生更大的结果。
Chap3:分段机制和逻辑地址¶
寄存器和字长¶
处理器的位数,它是指寄存器和算术逻辑部件的数据宽度,这个宽度也叫作处理器的 字长。因此,8位处理器、16位处理器、32位处理器和64位处理器的字长也分别是8位、16位、32位和64位。
16位寄存器可以存放2字节,这称为 1个字(word),各个比特的编号分别是0~15,其中0~7是低字节,8~15是高字节。
32位寄存器可以存放4字节,这称为 1个双字(double word) ,各个数位的编号分别是0~31,其中,0~15是低字,16~31是高字。
64位寄存器可以容纳更多的比特,也就是8字节,或者4个字,简称 四字(quad word)。
内存访问和字节序¶
对于用得最多的个人计算机来说,内存按字节来组织,单次访问的最小单位是1字节,这是最基本的存储单元。如图所示,每个存储单元中,各位的编号分别是0~7。
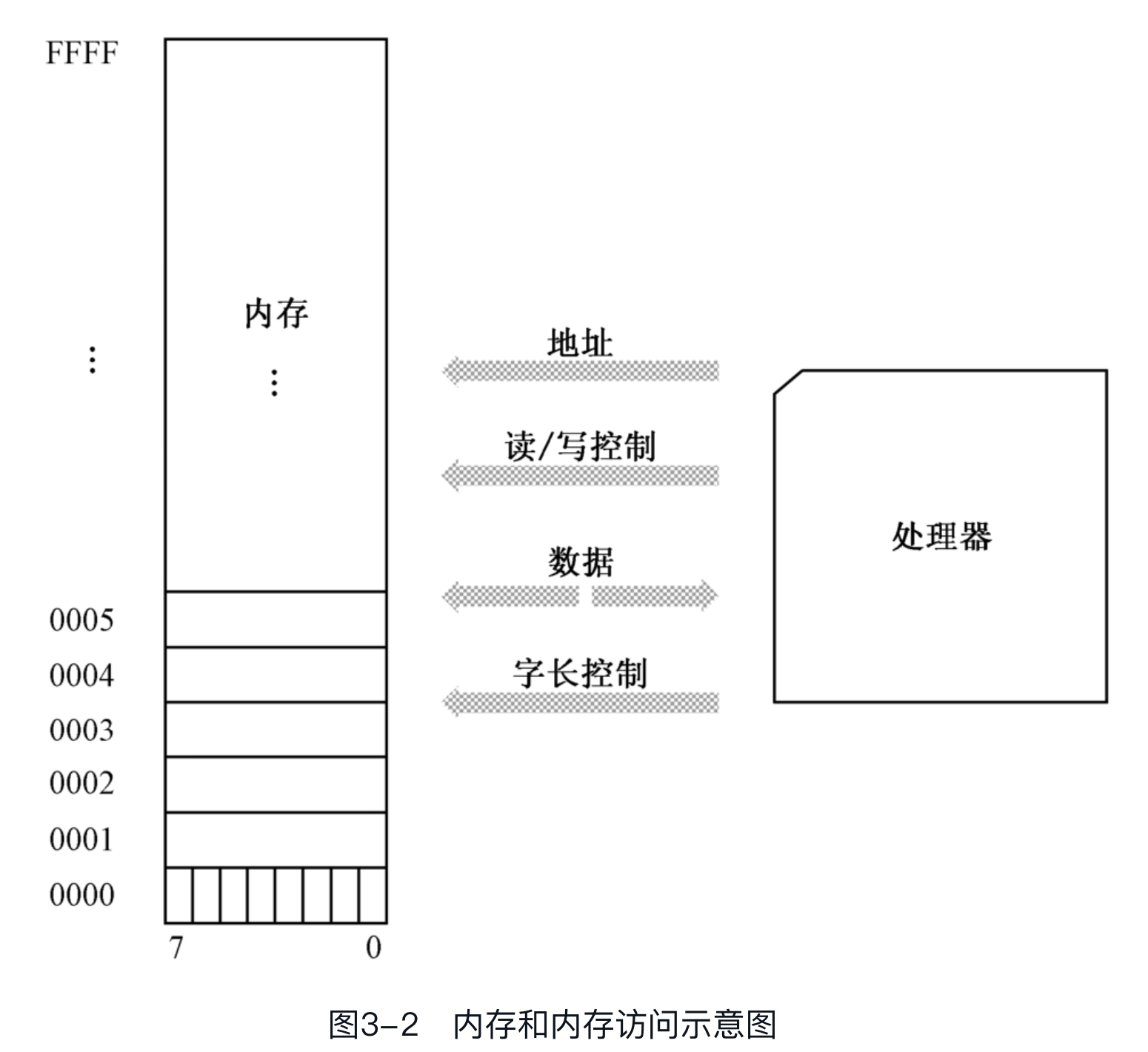
内存中的每字节都对应着一个地址,如上图所示,第1字节的地址是0000H,第2字节的地址是0001H,第3字节的地址是0002H,其他依次类推。注意,图中采用的是十六进制表示法。作为一个例子,因为这个内存的容量是65536字节,所以最后一字节的地址是FFFFH。
为了访问内存,处理器需要给出一个地址(对应地址总线)。访问包括读和写,为此,处理器还要指明,本次访问是读还是写(控制总线)。如果是写,还要给出待写入的数据。
处理器在工作时,需要在内存和寄存器之间交换数据。尽管内存的最小组成单位是字节,但是,经过精心的设计和安排,它 能够单次按字节、字、双字和四字进行访问。换句话说,仅通过单次访问就能处理8位、16位、32位或者64位的二进制数。注意,这里说的是单次访问,而不是一个一个地取出各字节,然后加以组合。
处理器发出字长控制信号,以指示本次访问的字长是8、16、32还是64。如果字长是8,而且给出的地址是0002H,那么,本次访问只会影响到内存的1字节;如果字长是16,给出的地址依然是0002H,那么实际访问的将是地址0002H处的一个字。对于INTEL处理器来说,如果访问内存中的一个字,那么,它规定高字节位于高地址部分,低字节位于低地址部分,这称为 低端字节序(Little Endian)。因此,低8位在0002H中,高8位在0003H中。至于其他公司的处理器,则可能情况正好相反,称为 高端字节序(Big Endian)。
古老的INTEL 8086处理器¶
8086是INTEL公司第一款16位处理器,诞生于1978年,所以说它很古老。
但是,在INTEL公司的所有处理器中,它占有很重要的地位,是整个INTEL 32位架构处理器(IA-32)的开山鼻祖。当我们讲述处理器的时候,必须要从8086开始;另外,要学习汇编语言,针对8086的汇编技术也是必不可少的。
8086的通用寄存器¶

8086处理器内部有8个16位的通用寄存器,都是由16比特组成的,并分别被命名为AX、BX、CX、DX、SI、DI、BP、SP。“通用”的意思是,它们之中的大部分都可以根据需要用于多种目的。
因为这8个寄存器都是16位的,所以通常用于进行16位的操作。比如,可以在这8个寄存器之间互相传送数据,它们之间也可以进行算术逻辑运算;也可以在它们和内存单元之间进行16位的数据传送或者算术逻辑运算。
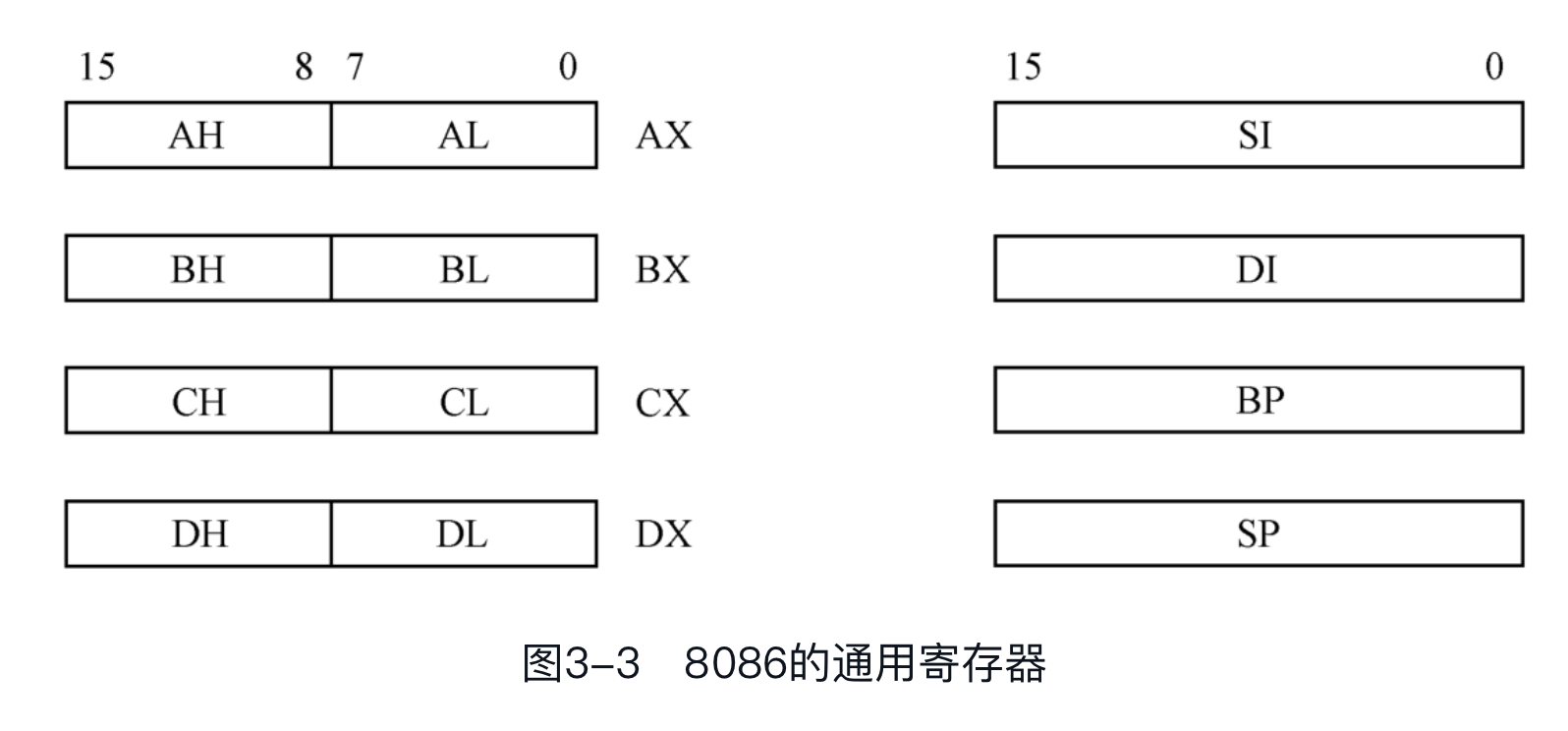
同时,如上图所示,这8个寄存器中的前4个,即AX、BX、CX和DX,又各自可以拆分成两个8位的寄存器来使用,总共可以提供8个8位的寄存器AH、AL、BH、BL、CH、CL、DH和DL。这样一来,当需要在寄存器和寄存器之间,或者寄存器和内存单元之间进行8位的数据传送或者算术逻辑运算时,使用它们就很方便。
将一个16位的寄存器当成两个8位的寄存器来用时,对其中一个8位寄存器的操作不会影响到另一个8位寄存器。举个例子来说,当你操作寄存器AL时,不会影响到AH中的内容。
8086的内存分段机制¶
逻辑地址¶
为了解决程序中指令和数据加载问题,采用分段机制。当采用分段策略之后,一个内存单元的地址实际上就可以用“段:偏移”或者“段地址:偏移地址”来表示,这就是通常所说的 逻辑地址。
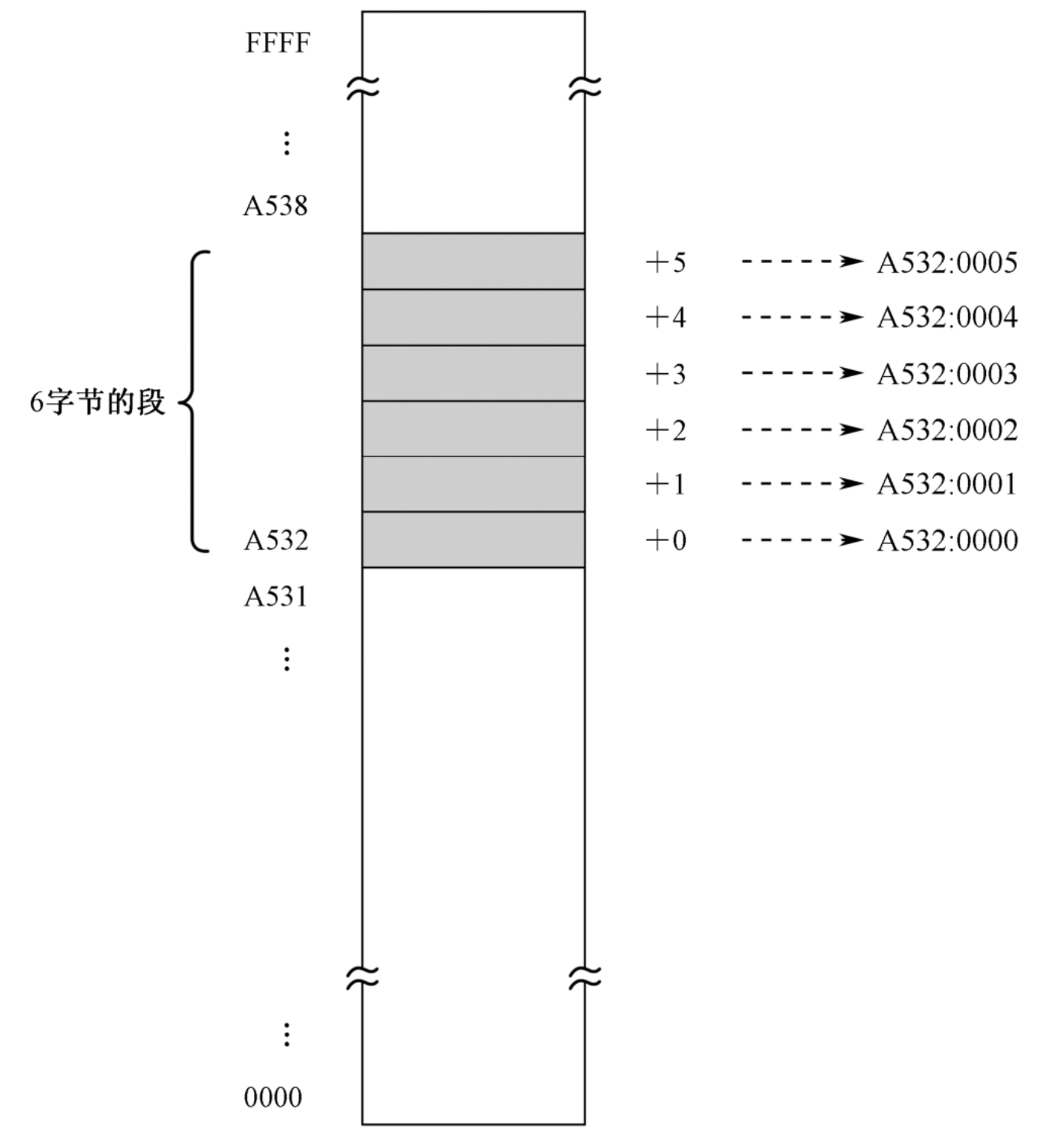
比如,在下图中,段内第1个存储单元的地址为A532H:0000H,第3个存储单元的地址为A532H:0002H,而本段最后一个存储单元的地址是A532H:0005H。
为了在硬件一级提供对“段地址:偏移地址”内存访问模式的支持,处理器至少要提供两个段寄存器,分别是代码段寄存器(Code Segment, CS)和数据段寄存器(Data Segment, DS)。
对代码段寄存器CS的改变将导致处理器从新的代码段开始执行。同样,在开始访问内存中的数据之前,也必须首先设置好数据段寄存器DS,使之指向数据段。
除此之外,最重要的是,当处理器访问内存时,它把指令中指定的内存地址看成段内的偏移地址(这也是为什么采用分段机制,因为当我们只要将CS/DS寄存器指定为程序加载后代码和数据在内存中的起始地址即可),而不是物理地址。这样,一旦处理器遇到一条访问内存的指令,它将把DS中的数据段起始地址和指令中提供的段内偏移相加,来得到访问内存所需要的物理地址。
代码段的段地址为1020H,数据段的段地址为1000H。在代码段中有一条指令A1 02 00,它的功能是将地址0002H处的一个字传送到寄存器AX中。在这里,处理器将0002H看成段内的偏移地址,段地址在DS中,应该在执行这条指令之前就已经用别的指令传送到DS中了。
当执行指令A1 02 00时,处理器将把DS中的内容和指令中指定的偏移地址0002H相加,得到1002H。这是一个物理地址,处理器用它来访问内存,就可以得到所需要的数00A0H。
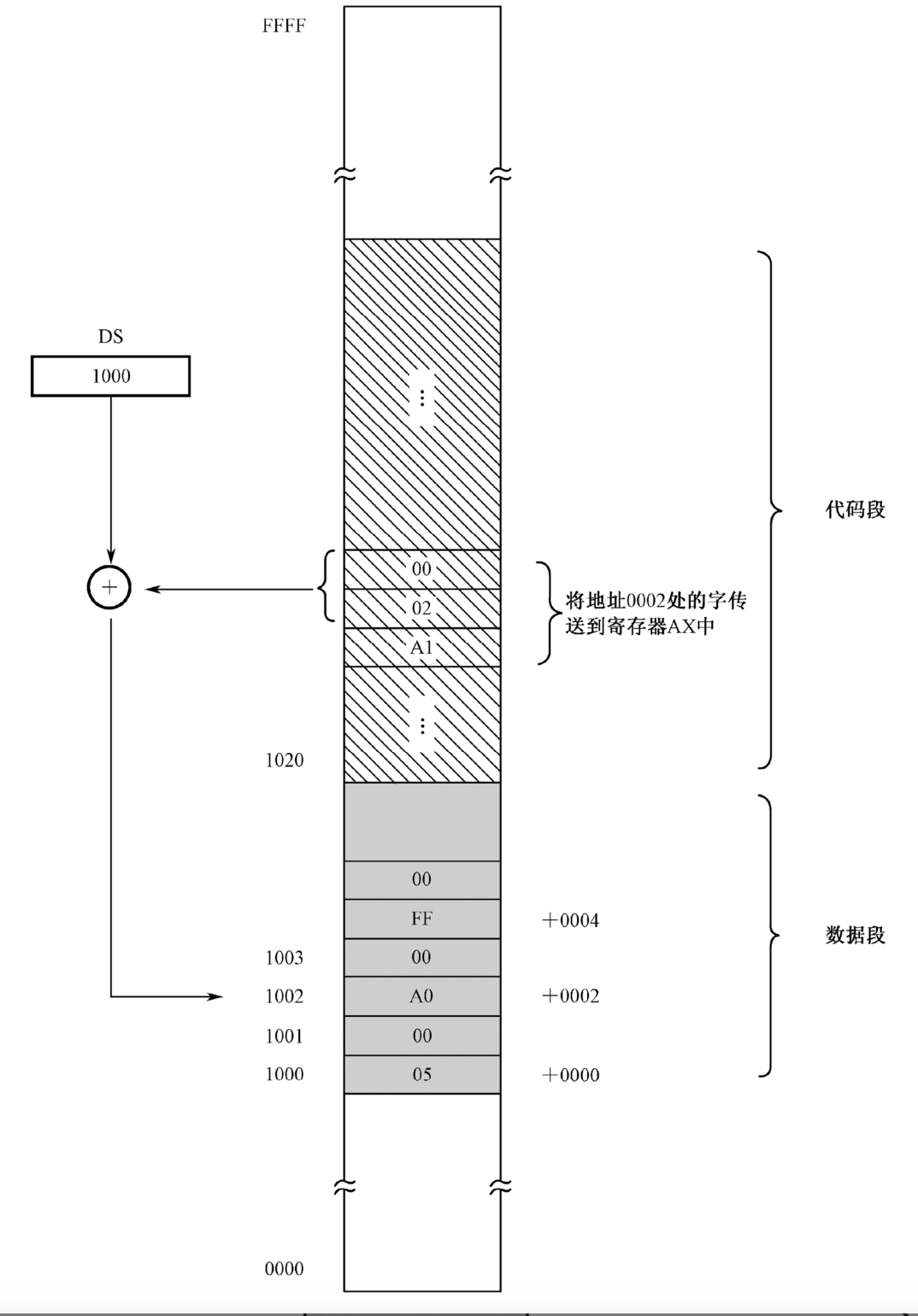
以上就是如何从逻辑地址转换到物理地址,以使程序的运行和它在内存中的位置无关。这种策略在很多处理器中得到了支持,包括8086处理器。但是,由于8086自身的局限性,它的做法还要复杂一些。
8086内部有8个16位的通用寄存器,分别是AX、BX、CX、DX、SI、DI、BP、SP。其中,前4个寄存器中的每个寄存器都还可以当成2个8位的寄存器来使用,分别是AH、AL、BH、BL、CH、CL、DH、DL。
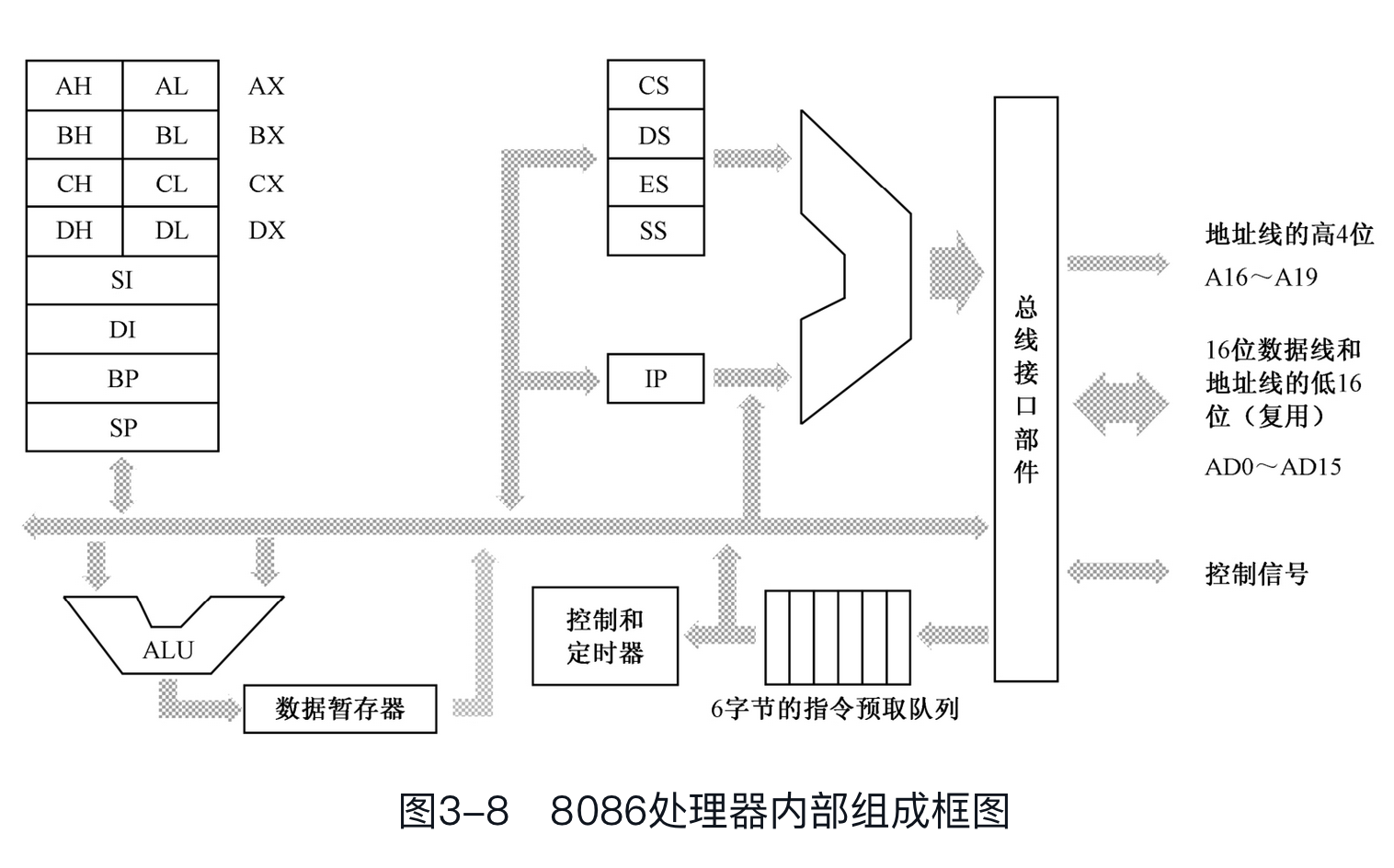
在进行数据传送或者算术逻辑运算的时候,使用 算术逻辑部件(ALU) 。比如,将AX的内容和CX的内容相加,结果仍在AX中,那么,在相加的结果返回到AX之前,需要通过一个叫数据暂存器的寄存器中转。
处理器能够自动运行,这是控制器的功劳。为了加快指令执行速度,8086内部有一个6字节的 指令预取队列,在处理器忙着执行那些不需要访问内存的指令时,指令预取部件可以趁机访问内存预取指令。这时,多达6字节的指令流可以排队等待解码和执行。
8086内部有4个段寄存器。其中,CS是代码段寄存器,DS是数据段寄存器,ES是附加段(Extra Segment)寄存器。附加段的意思是,它是额外赠送的礼物,当需要在程序中同时使用两个数据段时,DS指向一个,ES指向另一个。可以在指令中指定使用DS和ES中的哪一个,如果没有指定,则默认使用DS。SS是栈段(Stack Segment)寄存器,非常重要。
IP是指令指针(Instruction Pointer)寄存器,它只和CS一起使用,而且只有处理器才能直接改变它的内容。当一段代码开始执行时,CS保存代码段的段地址,IP则指向段内偏移。这样,由CS和IP共同形成逻辑地址,并由总线接口部件变换成物理地址来取得指令。然后,处理器会自动根据当前指令的长度来改变IP的值,使它指向下一条指令。
如果在指令的执行过程中需要访问内存单元,那么,处理器将用DS的值和指令中提供的偏移地址相加,来形成访问内存所需的物理地址。
8086的段寄存器和IP寄存器都是16位的,如果按照原先的方式,把段寄存器的内容和偏移地址直接相加来形成物理地址的话,也只能得到16位的物理地址。麻烦的是,8086却提供了20根地址线。换句话说,它提供的是20位的物理地址。
提供20根地址线的原因很简单,16位的物理地址只能访问64KB的内存,地址范围是0000H~FFFFH,共65536字节。这样的容量,即使在那个年代,也显得捉襟见肘。
所以,65536字节就是64KB,而20位的物理地址则可以访问多达1MB的内存,地址范围从00000H到FFFFFH。问题是,16位的段地址和16位的偏移地址相加,只能形成16位的物理地址,怎么得到这20位的物理地址呢?
在8086系统中,由于段寄存器长度的限制,段不能起始于任意位置,也不是所有内存地址都可以作为段地址,段只能起始于那些能够被16整除的物理内存地址。对8086处理器来说,将这样的内存地址除以16或者右移4位,得到的结果就是逻辑段地址,简称 段地址。要访问一个段,需要将段地址传送到段寄存器。
反过来,在用段寄存器的内容访问内存时,只需要在其十六进制形式的内容后面加0,就可以还原到原先的20位物理地址,这相当于乘以16,或者左移4位。如果段地址是3C7FH,它的二进制形式为0011110001111111。左移4位的意思是将所有比特同时向左移动4次,右边空出来的位置用4个0填充。因此,结果是一个16位的二进制数00111100011111110000,换算成十六进制是3C7F0H,这就是段的物理地址。
处理器访问内存时,光有段地址不行,还需要有偏移地址,它们共同组成了逻辑地址,而且处理器的总线接口部件负责把逻辑地址转换为物理地址。8086处理器在形成物理地址时,先将段寄存器的内容乘以16或者左移4位,形成20位的段地址,然后再同16位的偏移地址相加,得到20位的物理地址。比如,对于逻辑地址F000H:052DH,处理器在形成物理地址时,将段地址F000H左移4位,变成F0000H,再加上偏移地址052DH,就形成了20位的物理地址F052DH。对于下面指令,0xf000是要跳转的段地址,0xe05b是目标代码段内的偏移地址,用来改变IP寄存器的内容。因此,目标位置的物理地址是0xfe05b(0xf000<< 4 + 0xe05b)。:
这样,因为段寄存器是16位的,在段不重叠的情况下,最多可以将1MB的内存分成65536个段,段地址分别是0000H、0001H、0002H、0003H,…,FFFFH。在这种情况下,每个段正好16字节,偏移地址从0000H到000FH。
同样在不允许段之间重叠的情况下,每个段的最大长度是64KB,因为偏移地址也是16位的,从0000H到FFFFH。在这种情况下,1MB的内存,最多只能划分成16个段,每段长64KB,段地址分别是0000H、1000H、2000H、3000H,…,F000H。
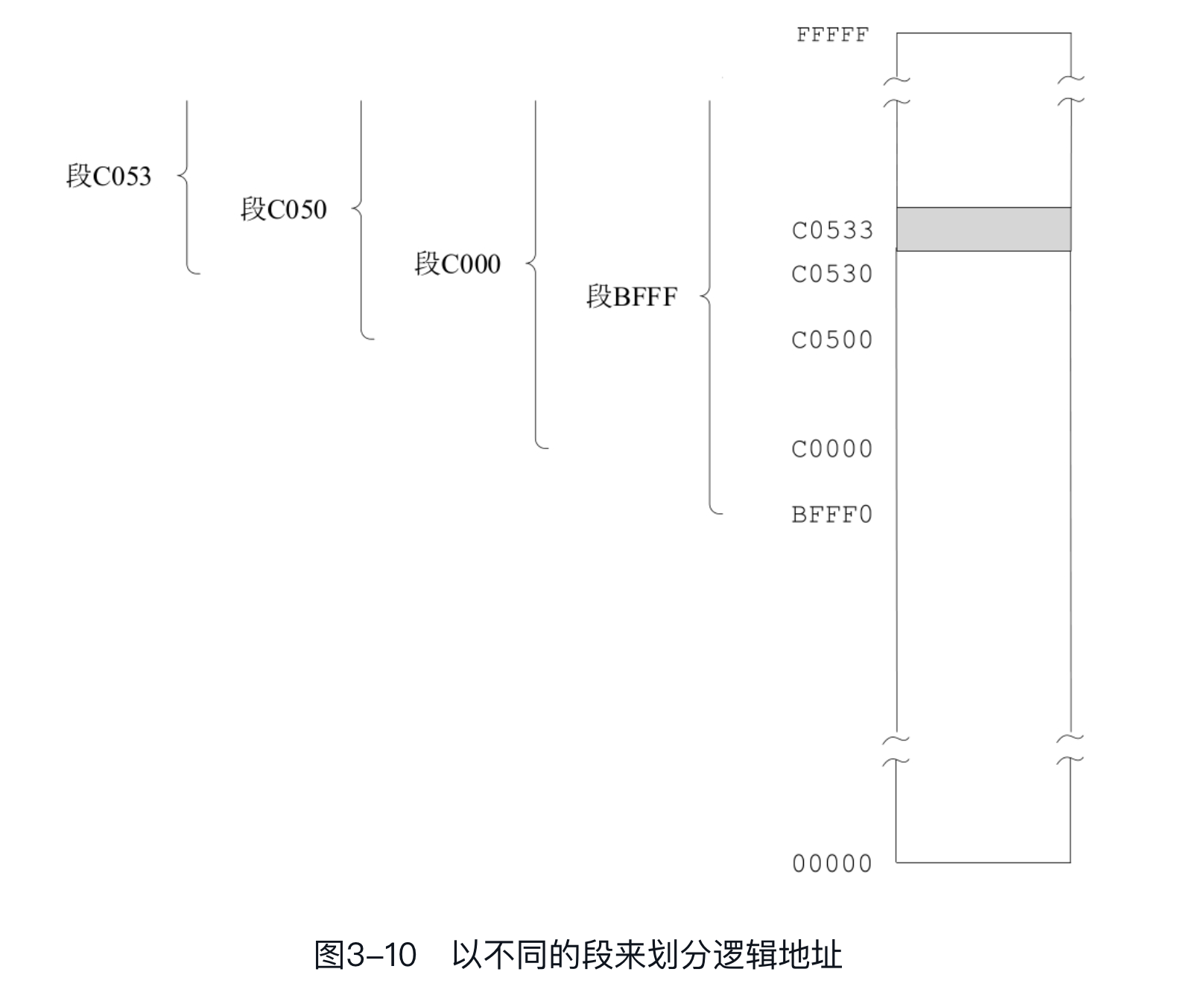
段的划分是自由的,它可以起始于任何16字节对齐的内存地址,也可以是任意长度,只要不超过64KB。也就是说,同一个物理地址,实际上对应多个逻辑地址。比如说,对于一个物理地址C0533H,它可以用逻辑地址C053H:0003H来表示,也可以用逻辑地址C000H:0530H来表示,还可以用逻辑地址C050H:0030H来表示,甚至用逻辑地址BFFFH:0540H来表示,等等。
如下图所示,对于上述的各种表示方法,实际上说明我们认为物理地址C0533H位于不同的段中,段地址分别为C053H、C050H、C000H和BFFFH。
Chap5: 虚拟机的安装与使用¶
计算机启动过程¶
计算机的加电和复位¶
在处理器众多的引脚中,有一个是RESET,用于接受复位信号。每当处理器加电,或者RESET引脚的电平由低变高时,处理器都会执行硬件初始化,以及一个可选的内部自测试(Build-in Self-Test, BIST),然后将内部所有寄存器的内容初始化到预置的状态。
比如,对于INTEL 8086来说,复位将使代码段寄存器(CS)的内容为0xFFFF,其他所有寄存器的内容都为0x0000,包括指令指针寄存器(IP)。8086之后的处理器并未延续这种设计,但毫无疑问,无论怎么设计,都是有目的的。
处理器的主要功能是取指令和执行指令,加电或者复位之后,它就会立刻尝试去做这样的工作。
基本输入输出系统¶
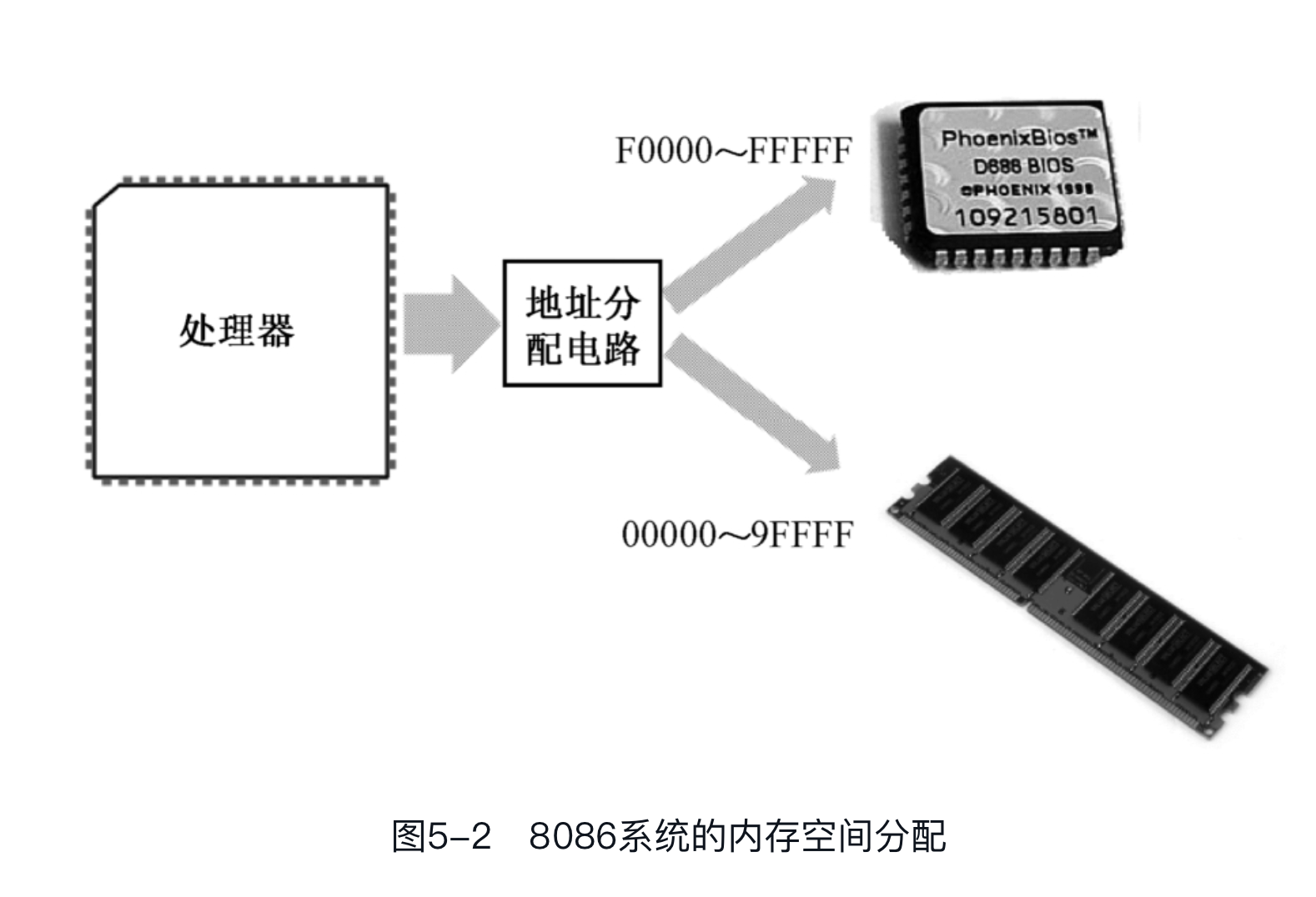
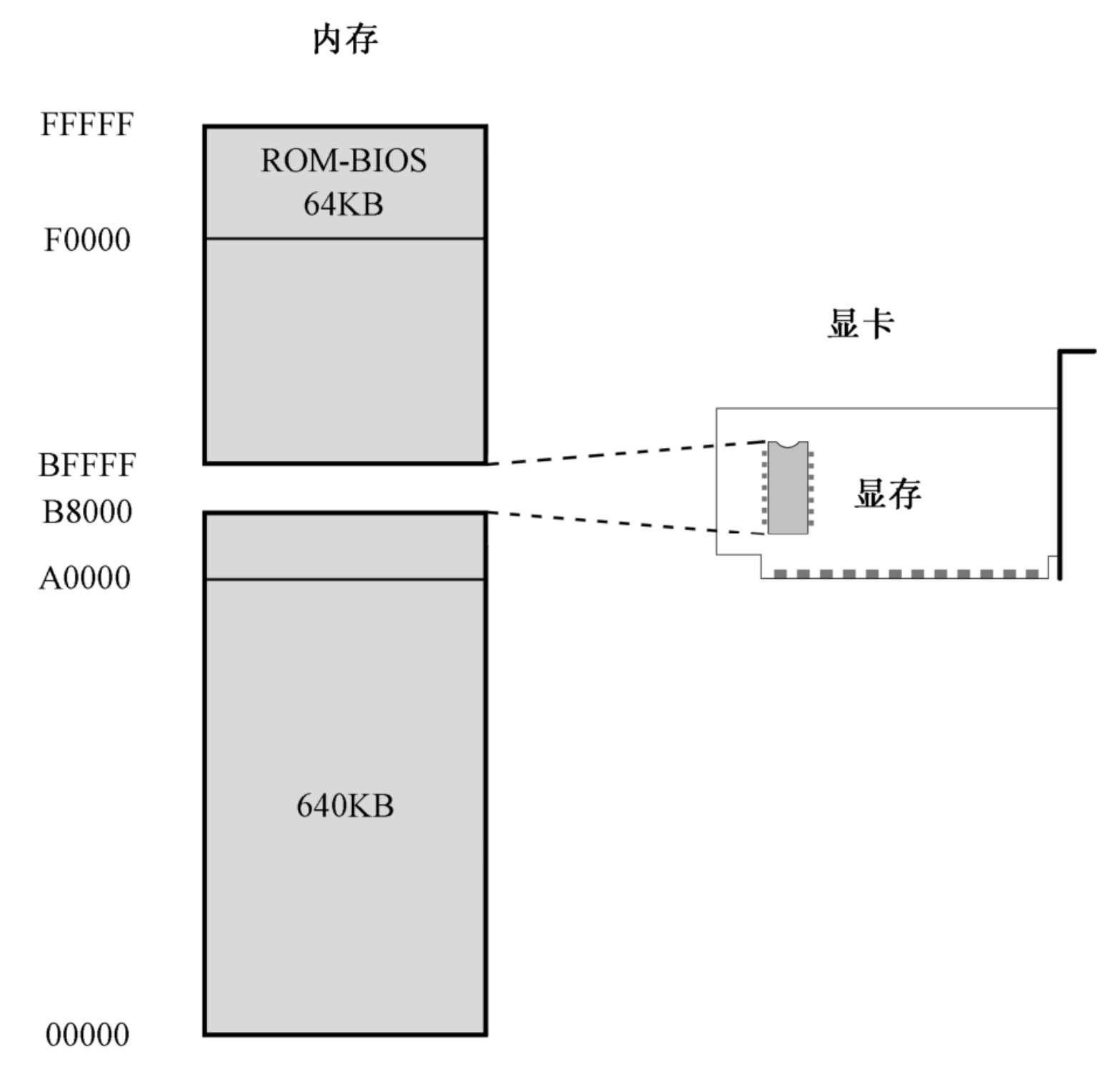
INTEL 8086可以访问1MB的内存空间,地址范围为0x00000到0xFFFFF。出于各方面的考虑,计算机系统的设计者将这1MB的内存空间从物理上分为几个部分。
8086有20根地址线,但并非全都用来访问DRAM,也就是内存条。事实上,这些地址线经过分配,大部分用于访问DRAM,剩余的部分给了只读存储器(Read Only Memory, ROM)和外围的板卡,如下图所示。
与DRAM不同,ROM不需要刷新,它的内容是预先写入的,即使掉电也不会消失,但也很难改变。这个特点很有用,比如,可以将一些程序指令固化在ROM中,使处理器在每次加电时都自动执行。处理器醒来后不能饿着,这是很重要的。
在以INTEL 8086为处理器的系统中,ROM占据着整个内存空间顶端的64KB,物理地址范围是0xF0000~0xFFFFF,里面固化了开机时要执行的指令;DRAM占据着较低端的640KB,地址范围是0x00000~0x9FFFF;中间还有一部分分给了其他外围设备。因为8086加电或者复位时,CS=0xFFFF,IP=0x0000,所以,它取的第一条指令位于物理地址0xFFFF0,正好位于ROM中,那里固化了开机时需要执行的指令。
处理器取指令执行的自然顺序是从内存的低地址往高地址推进。如果从0xFFFF0开始执行,这个位置离1MB内存的顶端(物理地址0xFFFFF)只有16字节的长度,一旦IP寄存器的值超过0x000F,比如IP=0x0011,那么,它与CS一起形成的物理地址将因为溢出而变成0x00001,这将回绕到1MB内存的最底端。
所以,ROM中位于物理地址0xFFFF0的地方,通常是一个跳转指令,它通过改变CS和IP的内容,使处理器从ROM中的较低地址处开始取指令执行。在NASM汇编语言里,一个典型的跳转指令像这样:
在这里,“jmp”是跳转(jump)的简化形式;0xf000是要跳转到的段地址,用来改变CS寄存器的内容;0xe05b是目标代码段内的偏移地址,用来改变IP寄存器的内容。因此,目标位置的物理地址是0xfe05b。一旦执行这条指令,处理器将开始从指定的“段:偏移”处开始重新取指令执行。
这块ROM芯片中的内容包括很多部分,主要是进行硬件的诊断、检测和初始化。所谓初始化,就是让硬件处于一个正常的、默认的工作状态。最后,它还负责提供一套软件例程,让人们在不必了解硬件细节的情况下从外围设备(比如键盘)获取输入数据,或者向外围设备(比如显示器)输出数据。设备当然是很多的,所以这块ROM芯片只针对那些最基本的、对于使用计算机而言最重要的设备,而它所提供的软件例程,也只包含最基本、最常规的功能。正因为如此,这块芯片又叫基本输入输出系统(Base Input & Output System, BIOS)ROM,简称 ROM-BIOS。
硬盘及其工作原理¶
历史上,有多种辅助存储设备,比如软盘、光盘、硬盘、U盘等,相对于内存,它们就是人们常说的“外存”,即外存储器(设备)。
从软盘(Floppy Disk)启动计算机,这已经是过去的事了。软盘的尺寸比烟盒稍大一点,但是比较薄,采用塑料作为基片,上面是一层磁性物质,可以用来记录二进制位。这种塑料介质比较柔软,所以称为软盘。
在数据记录原理上和软盘很相似的设备是硬盘(Hard Disk, HDD),而且它们几乎是同一个时代的产物。但是,与软盘不同,硬盘是多盘片、密封、高转速的,采用铝合金作为基片,并在表面涂上磁性物质来记录二进制位。这就使得它的盘片具有较高的硬度,故称为硬盘。
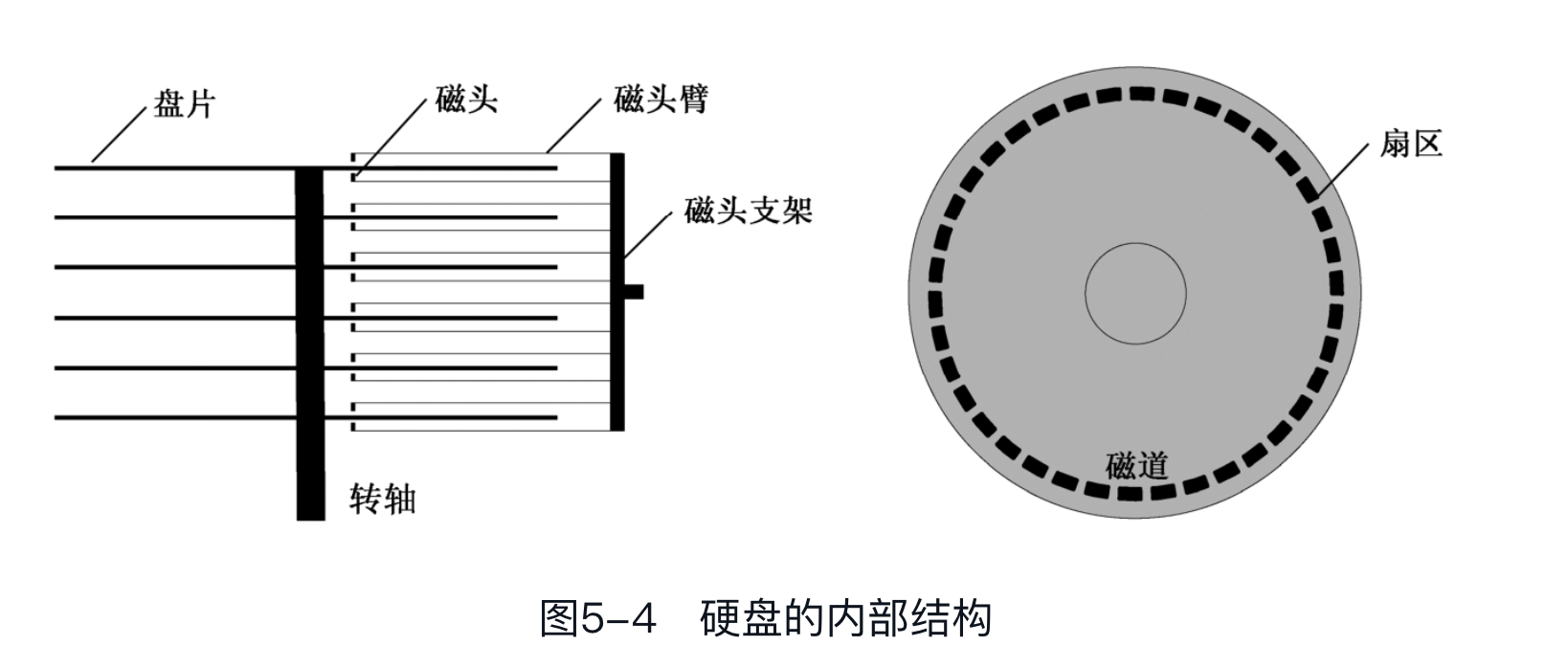
硬盘可以只有一个 盘片(这称为单碟),也可能有好几个盘片。但无论如何,它们都串在同一个轴上,由电动机带动着一起高速旋转。一般来说,转速可以达到每分钟3600转或者7200转,有的能达到一万多转,这个参数就是我们常说的“转/分”(Round Per Minute, RPM)。
每个盘片都有两个磁头(Head),上面一个,下面一个,经常用磁头来指代盘面。磁头都有编号,第1个盘片,上面的磁头编号为0,下面的磁头编号为1;第2个盘片,上面的磁头编号为2,下面的磁头编号为3,依次类推。
每个磁头不是单独移动的。相反,它们都通过磁头臂固定在同一个支架上,由步进电动机带动着一起在盘片的中心和边缘之间来回移动。也就是说,它们是同进退的。步进电动机由脉冲驱动,每次可以旋转一个固定的角度,即可以步进一次。
当盘片高速旋转时,磁头每步进一次,都会从它所在的位置开始,绕着圆心“画”出一个看不见的圆圈,这就是 磁道(Track)。磁道是数据记录的轨迹。因为所有磁头都是联动的,故每个盘面上的同一条磁道又可以形成一个虚拟的圆柱,称为 柱面(Cylinder)。
磁道,或者柱面,也要编号。编号从盘面最边缘的那条磁道开始,向着圆心的方向,从0开始编号。实际上,磁道还不是硬盘数据读写的最小单位,磁道还要进一步划分为 扇区(Sector)。
每条磁道能够划分为几个扇区,取决于磁盘的制造者,但通常为63个。而且,每个扇区都有一个编号,与磁头和磁道不同,扇区的编号是从1开始的。
扇区与扇区之间以间隙(空白)间隔开来,每个扇区以扇区头开始,然后是512字节的数据区。扇区头包含了每个扇区自己的信息,主要有本扇区的磁道号、磁头号和扇区号,用来定位。现代的硬盘还会在扇区头部包括一个指示扇区是否健康的标志,以及用来替换该扇区的扇区地址。用于替换扇区的,是一些保留和隐藏的磁道。
虚拟硬盘(VHD)¶
要访问硬盘,运行中的程序必须至少向硬盘控制器提供4个参数,分别是磁头号、磁道号、扇区号,以及访问意图(是读还是写)。
硬盘的读写是以扇区为最小单位的。所以,无论什么时候,要从硬盘读数据,或者向硬盘写数据,至少得是1个扇区。
你可能想,我只有2字节的数据,不足以填满一个扇区,怎么办呢?这是你自己的事。你可以用无意义的废数字来填充,凑够一个扇区的长度,然后写入。读取的时候也是这样,你需要自己跟踪和把握从扇区里读到的数据,哪些是你真正想要的。
VHD(Virtual Hard Disk)是微软公司的虚拟硬盘规范。VHD规范最早起源于Connectix公司的虚拟机软件Connectix Virtual PC,2003年,微软公司收购了它并改名为Microsoft Virtual PC。2006年,微软公司正式发布了VHD虚拟硬盘格式规范。
VHD分为两种类型:固定尺寸的和动态分配的。一个固定尺寸的VHD,它对应的文件尺寸和该虚拟硬盘的容量是相同的,或者说是一次性分配够了的。比如,一个2GB的VHD虚拟硬盘,它对应的文件大小也是2GB。
为了标志一个文件是VHD格式的虚拟硬盘,并为使用它的虚拟机提供该硬盘的参数,在VHD文件的结尾,包含了512字节的格式信息。VHD的文件尾信息是以一个字符串“conectix”开始的。
在VHD规范里,每个扇区是512字节。VHD文件一开始的512字节就对应着物理硬盘的0面0道1扇区。然后,VHD文件的第二个512字节,对应着0面0道2扇区,后面的依次类推,一直对应到0面0道n扇区。这里,n等于每磁道的扇区数。
再往后,因为硬盘的访问是按柱面进行的,所以,在VHD文件中,紧接着前面的数据块,下一个数据块对应的是1面0道1扇区,就这样一直往后排列,当把第一个柱面全部对应完后,再从第二个柱面开始对应。
VDI是VirtualBox自己的虚拟硬盘规范,VMDK是VMWare的虚拟硬盘规范。
逻辑块地址(LBA)¶
通常,一个扇区的尺寸是512字节,可以看成一个数据块。所以,从这个意义上来说,硬盘是一个典型的块(Block)设备。
采用磁头(Head)、磁道(Cylinder)和扇区(Sector)这种模式来访问硬盘的方法称为CHS模式,但不是很方便。想想看,如果有一大堆数据要写,还得注意磁头号、磁道号和扇区号不要超过界限。所以,后来引入了 逻辑块地址(Logical Block Address, LBA) 的概念。现在市场上销售的硬盘,无论哪个厂家生产的,都支持LBA模式。
LBA模式由硬盘控制器在硬件一级上提供支持,所以效率很高,兼容性很好。LBA模式不考虑扇区的物理位置(磁头号、磁道号),而是把它们全部组织起来统一编号。在这种编址方式下,原先的物理扇区被组织成逻辑扇区,且都有唯一的逻辑扇区号。
比如,某硬盘有6个磁头,每面有1000个磁道,每磁道有17个扇区。那么:
逻辑0扇区对应着0面0道1扇区;
逻辑1扇区对应着0面0道2扇区;
……
逻辑16扇区对应着0面0道17扇区;
逻辑17扇区对应着1面0道1扇区;
逻辑18扇区对应着1面0道2扇区;
……
逻辑33扇区对应着1面0道17扇区;
逻辑34扇区对应着2面0道1扇区;
逻辑35扇区对应着2面0道2扇区;
……
要注意到,扇区在编号时,是以柱面为单位的。即,先是0面0道,接着是1面0道,直到把所有盘面上的0磁道处理完,再接着处理下一个柱面。之所以这样做,是因为我们讲过,要加速硬盘的访问速度,最好不移动磁头。
因为这里总共有102000个扇区,故最后一个逻辑扇区的编号是101999,它对应着5面999道17扇区,这也是整个硬盘上最后一个物理扇区。
这里面的计算方法是:
这里,LBA是逻辑扇区号,C、H、S是想求得逻辑扇区号的那个物理扇区所在的磁道、磁头和扇区号。5面999道17扇区对应LBA是:
采用LBA模式的好处是简化了程序的操作,使得程序员不用关心数据在硬盘上的具体位置。VHD文件是按LBA方式组织的,一开始的512字节就是逻辑0扇区,然后是逻辑1扇区;最后一个逻辑扇区排在文件的最后(最后512字节除外,那是VHD文件的标识部分)。
一切从主引导扇区开始¶
ROM-BIOS在完成自己的使命之前,最后要做的一件事是从外存储设备读取更多的指令来交给处理器执行。现实的情况是,对于ROM-BIOS来说,绝大多数时候,硬盘都是首选的外存储设备。
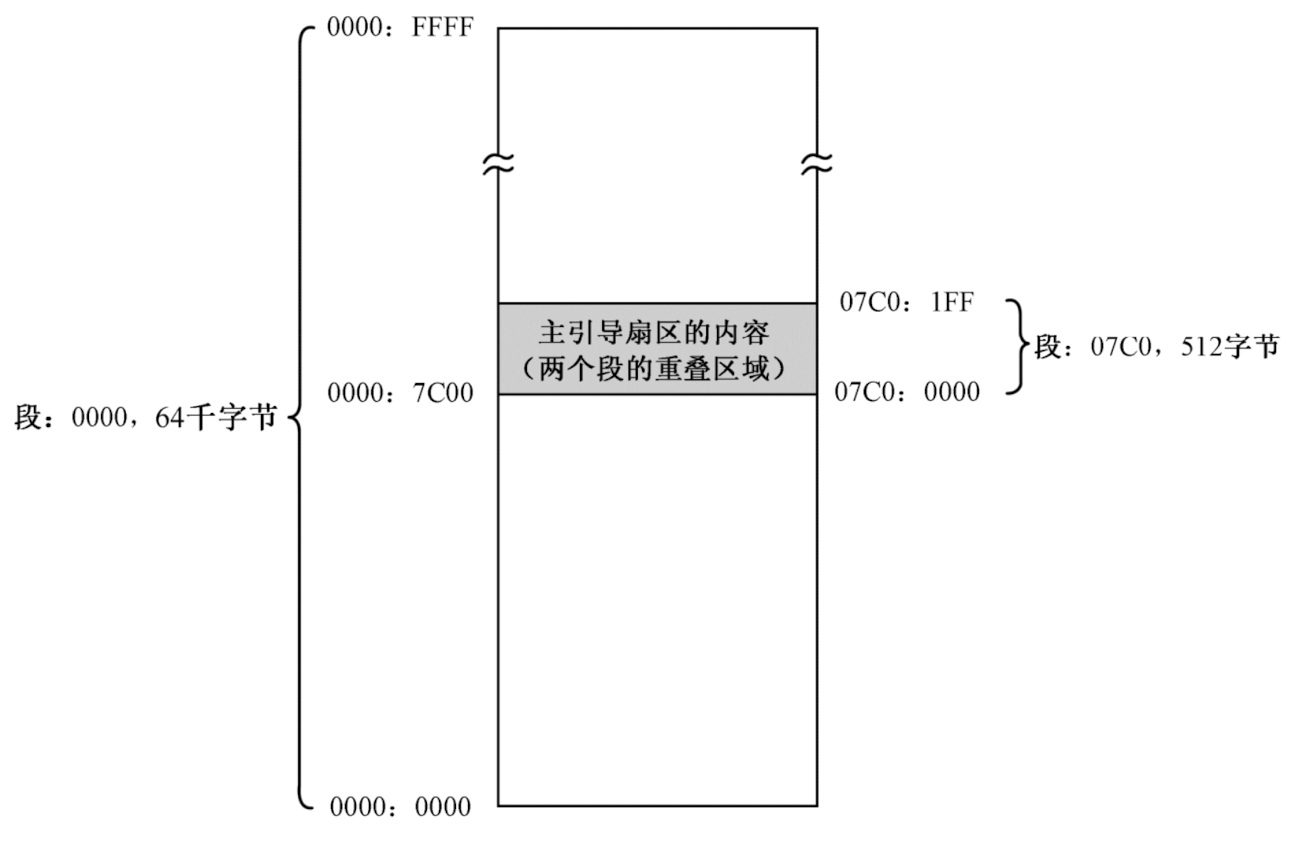
硬盘的第一个扇区是0面0道1扇区,或者说是0头0柱1扇区,这个扇区称为主引导扇区。如果计算机的设置是从硬盘启动的,那么,ROM-BIOS将读取硬盘主引导扇区的内容,将它加载到内存地址0x0000:0x7c00(也就是物理地址0x07C00),然后用一个jmp指令跳到那里接着执行:
为什么偏偏是0x7c00这个地方?还不太清楚。反正当初定下这个方案的家伙已经被人说了很多坏话,我也就不准备再多说什么了。
通常,主引导扇区的功能是继续从硬盘的其他部分读取更多的内容加以执行。像Windows这样的操作系统,就是采用这种接力的方法一步一步把自己运行起来的。
Chap6:编写主引导扇区代码¶
在屏幕上显示文字¶
黑色和白色只需要1比特就能表示,但要显示更多的颜色,1比特就不够了。现在最流行的,是用24比特,即3字节,来对应一个像素。因为224=16777216,所以在这种模式下,同屏可以显示16777216种颜色,这称为 真彩色。
我们知道,8086可以访问1MB内存。其中,0x00000~9FFFF属于常规内存,由内存条提供;0xF0000~0xFFFFF由主板上的一个芯片提供,即ROM-BIOS。
这样一来,中间还有一个320KB的空洞,即0xA0000~0xEFFFF。传统上,这段地址空间由特定的外围设备来提供,其中就包括显卡。因为显示的功能对于现代计算机来说实在是太重要了。
由于历史的原因,所有在个人计算机上使用的显卡,在加电自检之后都会把自己初始化为80×25的文本模式。在这种模式下,屏幕上可以显示25行,每行80个字符,每屏总共2000个字符。
所以,如下图所示,一直以来,0xB8000~0xBFFFF这段物理地址空间,是留给显卡的,由显卡来提供,用来显示文本。
考虑到文本模式下显存的起始物理地址是0xB8000,这块内存可以看成段地址为0xB800,偏移地址从0x0000延伸到0xFFFF的区域,因此我们可以把段地址定为0xB800。
访问内存可以使用段寄存器DS,但这不是强制性的,也可以使用ES。因为DS还有别的用处,所以在这里我们使用ES来指向显存所在的段。
INTEL处理器不允许将一个立即数传送到段寄存器,所以设置es段寄存器时候,先把0xb800保存到ax中,然后将ax值搬运到es寄存器中。
接下来输出Label,注意下面是intel风格的汇编:
;以下显示字符串Label
mov byte [es:0x00],'L'
mov byte [es:0x01],0x07
mov byte [es:0x02],'a'
mov byte [es:0x03],0x07
mov byte [es:0x04],'b'
mov byte [es:0x05],0x07
mov byte [es:0x06],'e'
mov byte [es:0x07],0x07
mov byte [es:0x08],'l'
一般情况下,如果没有附加任何指示,段地址默认在段寄存器DS中。比如mov byte [0x00],'L',如果使用其他段寄存器,那么需要显示指定:mov byte [es:0x00],'L'。
xor,在数字逻辑里是异或(eXclusive OR)的意思,或者叫互斥或、互斥的或运算。指令xor dx,dx中的目的操作数和源操作数相同,那么,不管寄存器DX中的内容是什么,两个相同的数字异或,其结果必定为0,故这相当于将寄存器DX清零。
使程序进入无限循环状态¶
两种jmp的区别¶
当编译器看到jmp之后是一个绝对地址,如0xF000:0x2000时,它就知道应当编译成使用操作码0xEA的直接绝对转移指令。
相反地,如果编译器发现jmp之后是一个标签时候,那么,它就会编译成使用操作码为0xE9的相对转移指令。关键字“near”不是最主要的,它仅仅用于指示相对量是16位的,是相对近转移。
程序的调试技术¶
Bochs下的程序调试入门¶
第一步执行下面命令启动bochs:
Bochs的“处理器”在加电之后,要开始取指令并执行指令。但是,与真正的处理器不同,如下图所示,Bochs在执行它启动之后的第一条指令时,会停下来,等待你的调试命令。
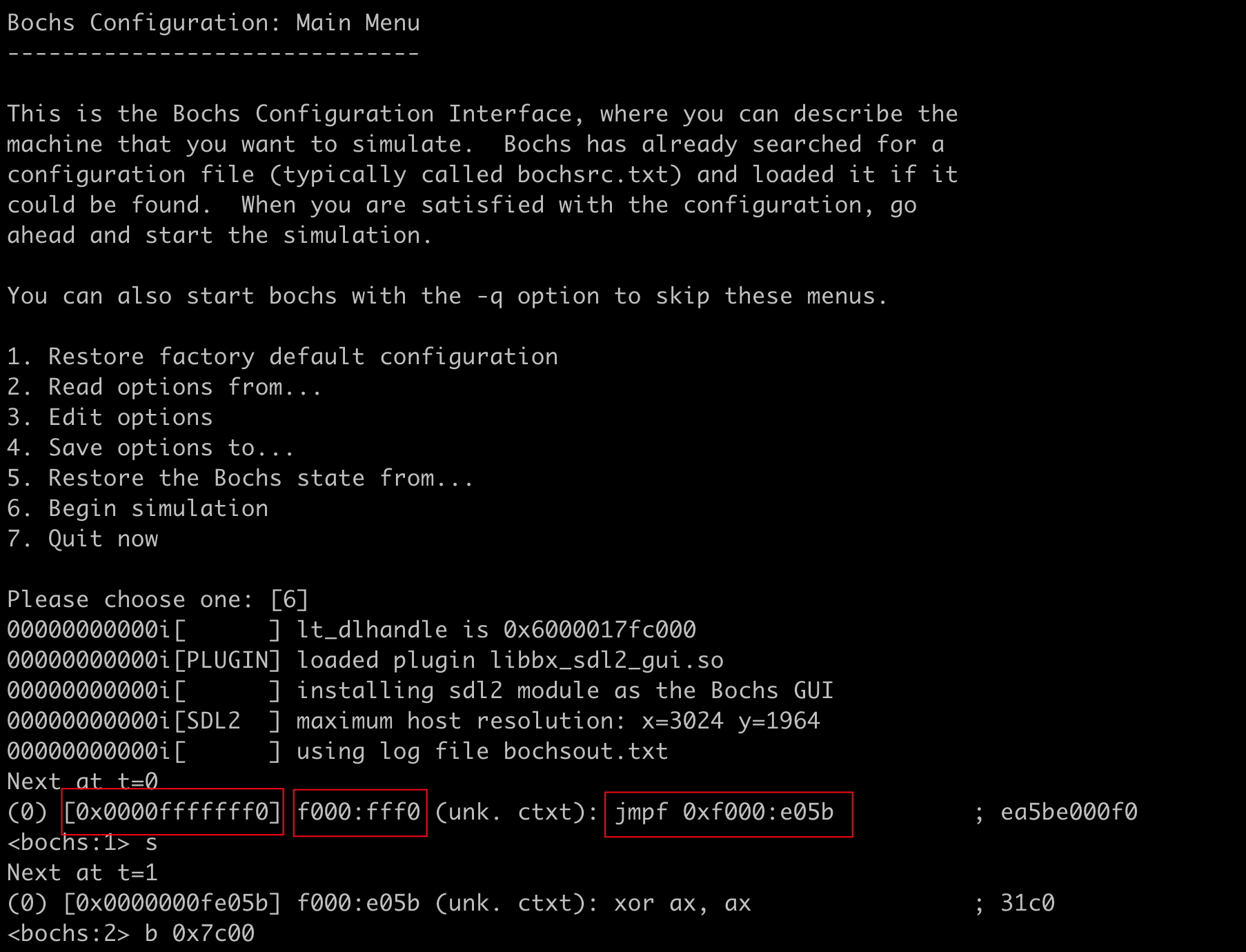
从上面我们可以看到:当前正在等待执行的那条指令,即“jmp far f000:e05b”。在这条指令中,关键字“far”是不必要的,而且在Bochs中,数值默认是十六进制的。该指令作用是转移目标位置到ROM-BIOS。
8086有20根地址线,加电启动之后,代码段寄存器CS的内容为0xFFFF,指令指针寄存器IP的内容为0x0000,因此,第一条指令的物理地址是20位的0xFFFF0。但是,8086处理器已经成为历史,它之后的处理器都能够兼容8086的功能,但却拥有超过32根的地址线。在当前的这个Bochs虚拟机上,地址线的数量超过了32根。因此,Bochs在这里用64位的宽度来显示物理地址。但是,它的值应该是0x00000000000FFFF0,不是吗?
事情是这样的,和8086不同,现代处理器在加电启动时,代码段寄存器CS的内容为0xF000,指令指针寄存器IP的内容为0xFFF0,这就使得处理器地址线的低20位同样是0xFFFF0。这还不算完,在刚刚启动时,处理器将其余(高位部分)的地址线强制为高电平。因为当前Bochs虚拟机的地址线是32根,所以,初始发出的物理内存地址就是0x00000000FFFFFFF0了。
之所以这样做,是因为处理器的设计者希望把ROM-BIOS放到4GB(32根地址线可提供的寻址范围是232=4GB)可寻址内存范围的最高端,这样,4GB以下,连同传统的低端1MB都是连续的RAM区,连续的、不间断的RAM能为操作系统管理内存带来方便。
在物理地址的后边,是逻辑地址,即代码段寄存器CS和指令指针寄存器IP的内容,是以十六进制显示的,等效于0xf000:0xfff0。在这一行的右边,Bochs还以注释的形式显示了指令的机器代码,即EA 5B E0 00 F0。
单步执行命令是“s”(step)。如上图所示,输入“s”命令后回车,Bochs执行刚才那条指令,然后停下来,同时显示下一条即将执行的指令。指令执行后,下一条等待执行的指令为xor ax,ax,对应的机器指令码为31 C0,所在的物理内存地址是0x0000000fe05b。
接下来,你可以继续单步执行。但是,老在BIOS中转悠也没什么意思。要知道,你调试的程序位于主引导扇区中,依靠单步执行得什么时候才能执行到主引导扇区代码!
不用担心,Bochs提供了断点指令“b”(break)。所谓断点,就是事先设置一个(物理)内存地址,当处理器执行到这个地址时,就自动停下来。因为计算机启动后,总是把主引导程序加载到物理内存地址0x7c00处,所以,可以将这个地址设为断点。
使用调试命令“n”。此时,Bochs将自动完成循环过程,并在循环体外的下一条指令前停住。
"u"命令是反汇编指令(反汇编的意思是根据机器指令代码生成可读的汇编语言指令,正好与汇编过程相反)可以使用两个参数,第一个参数是跟在“/”后面的数字,指定反汇编出多少条指令;第二个参数用于指定一个内存地址,Bochs从这里开始反汇编操作。
为了查看标志寄存器FLAGS的状态(各个标志位),可以在Bochs中使用命令“info”。
为了显示标志寄存器的状态,可以使用“eflags”参数,即“info eflags”。INTEL8086的标志寄存器是16位的,称作FLAGS;在32位处理器上,该标志寄存器做了扩展,达到了32位,称作EFLAGS。因此,在Bochs中,应当输入“info eflags”,而不是“info flags”。
怎么知道某个标志位是“0”还是“1”呢?很简单,如果显示的标志名称是小写的,那么,说明该标志为“0”;否则,该标志的状态为“1”。
在Bochs中查看栈的命令是“print-stack”,它可以带一个参数,用于指定显示多少数据。如果不使用参数,则默认显示当前栈中的16个字。
Chap7:相同的功能,不同的代码¶
不同的段基址,相同内存区域¶
逻辑地址[0x0000:0x7c00]到[0x0000:FFFF]的内存区域,和逻辑地址[0x7c0:0x000]到[0x7c0:0x1FF]的内存区域是一致的。如下所示:
批量传输数据指令¶
movsb指令¶
- 传输单元为字节
- 16位模式下:源地址是DS:SI,目的地址是ES:DI
- 32位模式下:源地址是DS:ESI,目的地址是ES:EDI
- FLAGS寄存器的DF(Direction Flag)决定其正向传输还是反向传输
- CX指定传送的字节数(movsb)或者字的个数(movsw)或者双字个数,每传送一次,CX的内容自动减1
- 正向传送时,传送之后SI和DI(或者ESI和EDI)的值会减一,反之加一
movsw指令¶
- 传输单元为位字
- 同movsb的2到5点
- 正向传送时,传送之后SI和DI(或者ESI和EDI)的值会减二,反之加二
movsd指令¶
- 传输单元为双字(double word)
- 同movsb的2到5点
- 正向传送时,传送之后SI和DI(或者ESI和EDI)的值会减4,反之加4
注意:
- 正向传送是指传送操作的方向是从内存区域的低地址端到高地址端;反向传送则正好相反
- movsb和movsw只能执行一次,如果希望处理器自动地反复执行,需要加上指令前缀rep (repeat),意思是CX不为零则重复。rep movsw的操作码是0xF30xA5,它将重复执行movsw直到CX的内容为零。
- cld指令用来清除DF标志位,std指令用来设置DF标志位
loop指令¶
loop指令的功能是重复执行一段相同的代码,处理器在执行它的时候会顺序做两件事:
- 将寄存器 CX的内容减1;
- 如果寄存器 Cx 的内容不为零,转移到指定的位置处执行,否则顺序执行后面的指令。
在8086处理器上,如果要用寄存器来提供偏移地址,只能使用寄存器BX、SI、DI、BP,不能使用其他寄存器。
原因很简单,寄存器BX最初的功能之一就是用来提供数据访问的基地址,所以又叫基址寄存器(Base Address Register)。之所以不能用寄存器SP、IP、AX、CX、DX,这是一种硬性规定,说不上有什么特别的理由。
注意,可以在任何带有内存操作数的指令中使用寄存器BX、SI或者DI提供偏移地址。
inc指令¶
inc是加1指令,操作数可以是寄存器,也可以是字节或者字内存单元。从功能上讲,它和add bx 1指令是一样的,但前者的机器码更短,速度更快。
第一条指令执行时,处理器将寄存器AL中的内容加1;
第二条指令执行时,将寄存器BX所指向的内存单元的内容加1。就是说,处理器用段寄存器DS的内容左移4位,加上寄存器BX的内容,形成20位物理地址。然后,将该地址处的内容(字节)加1。
第三条指令和第二条指令做相同的事情,但是偏移地址是用标号给出的。关键字“word”表明它操作的是内存中的一个字,段地址在段寄存器DS中,偏移地址等于标号label_a在编译阶段的汇编地址。
示例¶
jmp near start
mytext db 'L',0x07,'a',0x07,'b',0x07,'e',0x07,'l',0x07,' ',0x07,'o',0x07,\
'f',0x07,'f',0x07,'s',0x07,'e',0x07,'t',0x07,':',0x07
number db 0,0,0,0,0
start:
mov ax,0x7c0 ;设置数据段基地址
mov ds,ax
mov ax,0xb800 ;设置附加段基地址
mov es,ax
cld; Clears the DF flag in the EFLAGS register
mov si,mytext ; 将字符串mytext起始地址保存到si寄存器中
mov di,0
mov cx,(number-mytext)/2 ; number的起始地址减去mytext的起始地址为mytext的字节个数,除以2是用来获取字个数。
rep movsw ; 重复移动mytext到 0xb800<<4地址处
;得到标号所代表的偏移地址
mov ax,number
;计算各个数位
mov bx,ax
mov cx,5 ;循环次数
mov si,10 ;除数
digit:
xor dx,dx
div si
mov [bx],dl ;保存数位
inc bx
loop digit
;显示各个数位
mov bx,number
mov si,4
show:
mov al,[bx+si]
add al,0x30
mov ah,0x04
mov [es:di],ax
add di,2
dec si
jns show
mov word [es:di],0x0744
jmp near $
times 510-($-$$) db 0
db 0x55,0xaa
计算机中的负数¶
-1 与 -2¶
-1其实等于0-1,也就是用二进制数0减去二进制数1,结果是:
注意左边的省略号,这是因为在相减的过程中,不停地向左边借位的结果。因此,可以说,这个数字是很长的,取决于你什么时候停止借位。再比如十进制数-2,可以用0-2来得到,在二进制的世界里,该减法是二进制数0减去二进制数10,结果是:
同样,相减的过程要向左借位,所以这个数字相当长。但是,最右边那一位是0。
neg指令¶
neg指令带有一个操作数,可以是8位或者16位的寄存器,或者内存单元,如:
它的功能很简单,用0减去指令中指定的操作数。例如,如果寄存器AL中的内容是00001000(十进制数8),执行neg al后,寄存器AL中的内容变为11111000(十进制数-8);如果寄存器AL中的内容为11000100(十进制数-60),执行neg al后,寄存器AL中的内容为00111100(十进制数60)。
cbw与cwd指令¶
一个8位的有符号数,要想用16位的形式来表示,只需将其最高位,也就是用来辨别符号的那一位(几乎所有的书上都称之为符号位,实际上这并不严谨),扩展到高8位即可。为了方便,处理器专门设计了两条指令来做这件事:cbw(Convert Byte to Word)和cwd(Convert Word to Double-word)。
cbw没有操作数,操作码为98。它的功能是,将寄存器AL中的有符号数扩展到整个寄存器AX。举个例子,如果寄存器AL中的内容为01001111,那么执行该指令后,寄存器AX中的内容为0000000001001111;如果寄存器AL中的内容为10001101,执行该指令后,寄存器AX中的内容为1111111110001101。
cwd也没有操作数,操作码为99。它的功能是,将寄存器AX中的有符号数扩展到DX:AX。举个例子,如果寄存器AX中的内容为0100111101111001,那么执行该指令后,寄存器DX中的内容为0000000000000000,寄存器AX中的内容不变;如果寄存器AX中的内容为1000110110001011,那么执行该指令后,寄存器DX中的内容为1111111111111111,寄存器AX中的内容同样不变。
尽管有符号数的最高位通常称为符号位,但并不意味着它仅仅用来表示正负号。事实上,通过上面的讲述和实例可以看出,它既是数的一部分,和其他比特一起共同表示数的大小,同时又用来判断数的正负。
处理器视角中的数据类型¶
即假如寄存器AX中的内容是0xB23C,那么,它到底是无符号数45628呢,还是应当将其看成-19908?
答案是,这是你自己的事,取决于你怎么看待它。对于处理器的多数指令来说,执行的结果和操作数的类型没有关系。换句话说,无论你是从无符号数的角度来看,还是从有符号数的角度来看,指令的执行结果都是正确无误的。
div和idiv指令¶
div指令是无符号除法指令(Unsigned Divide),因为这条指令只能工作于无符号数。换句话说,只有从无符号数的角度来解释它的执行结果才能说得通。
从无符号数的角度来看,0x0400等于十进制数1024,0xf0等于十进制数240。相除后,寄存器AL中的商为0x04,即十进制数4,完全正确。
但是,从有符号数的角度来看,0x0400等于十进制数1024,0xf0等于十进制数-16。理论上,相除后,寄存器AL中结果应当是0xc0。因其最高位是“1”,故为负数,即十进制数为-64。
为了解决这个问题,处理器专门提供了一个有符号数除法指令idiv(Signed Divide)。idiv的指令格式和div相同,除了它是专门用于计算有符号数的。如果你决定要进行有符号数的计算,必须采用如下代码:
在用idiv指令做除法时,需要小心。比如用0xf0c0除以0x10,也就是十进制数的除法-3904÷16。你的做法可能会是这样的:
以上的代码是16位二进制数除法,结果在寄存器AL中。除法的结果应当是十进制数-244,遗憾的是,这样的结果超出了寄存器AL所能表示的范围,必然因为溢出而不正确。为此,你可能会用32位的除法来代替以前的做法:
很遗憾,这依然是错的。十进制数-3904的16位二进制形式和32位二进制形式是不同的。前者是0xf0c0,后者是0xfffff0c0。还记得cwd吗?你应该用这条指令把寄存器AX中数的符号扩展到DX。所以,完全正确的写法是这样的:
以上指令全部执行后,寄存器AX中的内容为0xff0c,即十进制数-244。
div dest的含义是如下:
- 对于8位: AX(除数) % dest(被除数) = AL(商) AH(余数)
- 对于16位: DX:AX(除数) % dest(被除数) = AX(商) DX(余数)
- 对于32位: EDX:EAX(除数) % dest(被除数)= EAX(商) EDX(余数)
标志位与条件转移指令¶
根据INTEL手册可以得出结论,程序中我们不能直接修改EIP寄存器的值,即不允许我们使用类似MOV指令直接给EIP赋值,只能通过其他指令隐式地(implicitly)修改其值。这些指令包括JMP,Jcc,CALL,RET和IRET,还有CPU的中断和异常其实也是改变了EIP的值。
其中JMP,CALL,RET/IRET,中断和异常我们可以成为无条件分支(Unconditional Branches),而Jcc (jump on condition code cc)称为有条件分支(Conditional Branches)。
本文关注有条件分支。有条件分支是根据什么来决定跳转的呢?那就是EFLAGS寄存器中的状态标志(Status Flags)。
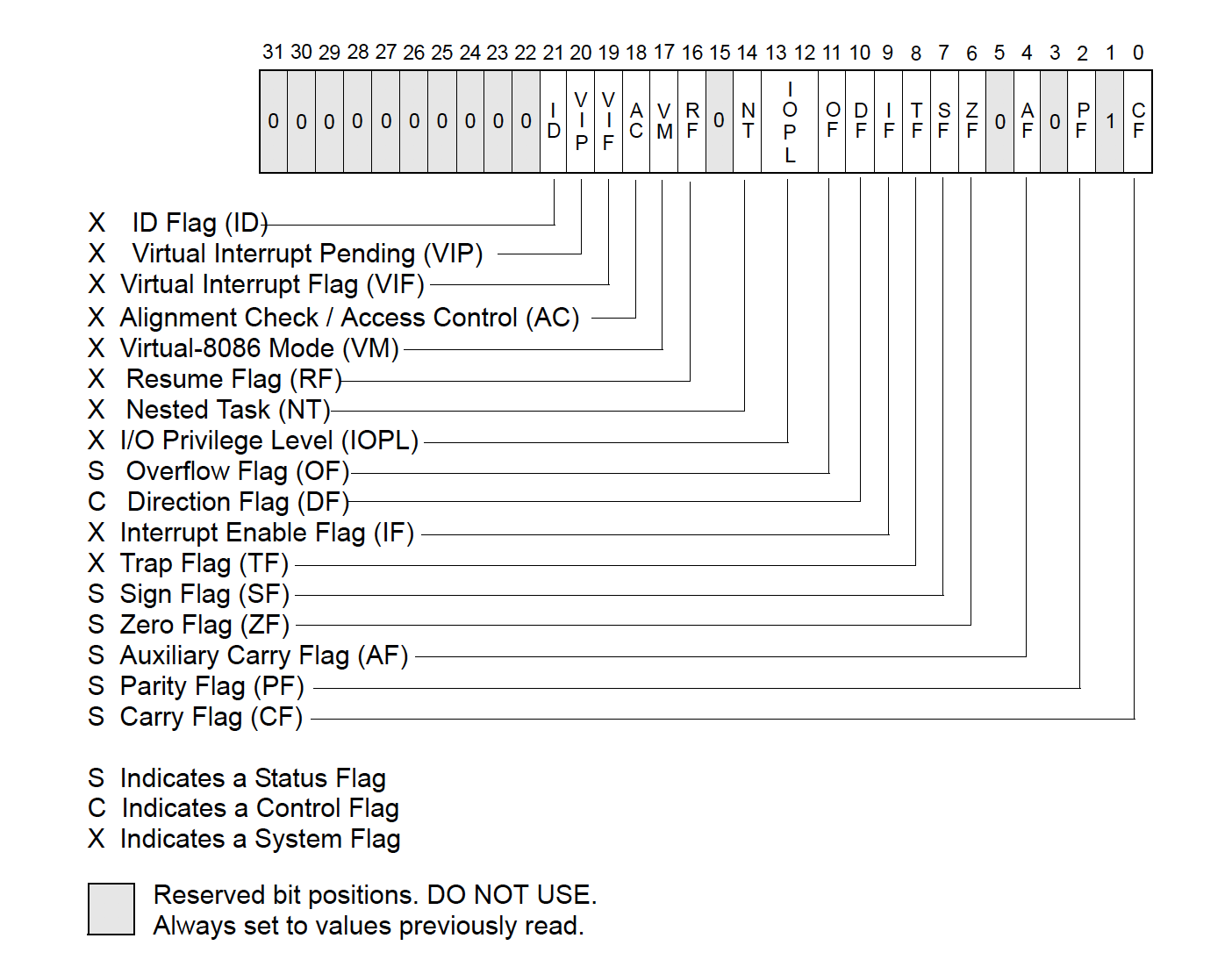
EFLAG寄存器,它是X86 CPU的状态寄存器。INTEL手册将EFLAGS中的标志按功能划分为三类,分别为状态标志(status flags)、控制标志(control flags)和系统标志(system flags)。FLAGS标志寄存器由一组状态标志、一个控制标志以、一组系统标志以及一部分保留未使用的位所组成。其状态标志用于表示逻辑或算术运算的结果,系统标志提供给操作系统使用。
| 名称 | 中文 | 作用 | 所属分类 | 说明 |
|---|---|---|---|---|
| CF | 进位标志(Carry flag) | 标志寄存器的第0位,又被称之为CY,当其被设置时表示运算结果的最高有效位发生进位或借位的情况,并在无符号整数的运算中表示运算的溢出状态。 | 状态标志 | 1. 状态标志用于指示算术运算(例如使用ADD、SUB、MUL、DIV等指令)后的结果。 2. 状态标志中,只有CF标志能被直接通过STC、CLC以及CMC指令修改。 |
| PF | 奇偶校验标志(Parity flag) | 标志寄存器的第2位,当其被设置表示结果中包含偶数个值为1的位,否则表示结果中包含奇数个值为1的位。 | 状态标志 | |
| AF | 辅助进位标志(Auxiliary carry flag) | 标志寄存器的第4位,当其被设置表示在算术运算中低三位发生进位或借位(例如AL向AH进位或借位)或BCD码算术运算中发生进位或借位的情况。 | 状态标志 | |
| ZF | 零标志(Zero flag) | 标志寄存器的第6位,当其被设置时运算的结果是否等于0,否则不等于0。 | 状态标志 | |
| SF | 符号标志(Sign flag) | 标志寄存器的第7位,当其被设置时表示结果为负数,否则为正数。 | 状态标志 | |
| OF | 溢出标志(Overflow flag) | 标志寄存器的第11位,当其被设置时代表运算结果溢出,即结果超出了能表达的最大范围。 | 状态标志 | |
| DF | 方向标志(Direction flag) | 标志寄存器的第10位,用于指示串操作指令地址的变化方向。当其被设置时,存储器由自高向低方向变化,否则相反。STD与CLD指令分别用于设置、清除DF标志的值。 | 控制标志 | |
| TF | 陷阱标志(Trap flag) | 标志寄存器的第8位,当其被设置时将开启单步调试模式。在其被设置的情况下,每个指令被执行后都将产生一个调试异常,以便于观察指令执行后的情况。 | 系统标志 | |
| IF | 中断标志(Interrupt flag) | 标志寄存器的第9位,当其被设置时表示CPU可响应可屏蔽中断(maskable interrupt) | 系统标志 | |
| IOPL | I/O特权级别标志(I/O privilege level flag) | 标志寄存器的第12位以及第13位,表示当其程序或任务的I/O权限级别。I/O权限级别为0~3范围之间的值,通常一般用户程序I/O特权级别为0。当前运行程序的CPL(current privilege level)必须小于等于IOPL,否则将发生异常。 | 系统标志 | |
| NT | 嵌套任务(Nested task flag) | 标志寄存器的第14位,用于控制中断返回指令IRET的执行方式。若被设置则将通过中断的方式执行返回,否则通过常规的堆栈的方式执行。在执行CALL指令、中断或异常处理时,处理器将会设置该标志。 | 系统标志 | |
| RF | 恢复标志(Resume flag) | 标志寄存器的第16位,用于控制处理器对调试异常的响应。若其被设置则会暂时禁止断点指令产生的调试异常,其复位后断点指令将会产生异常。 | 系统标志 | |
| VM | 虚拟8086模式标志(Virtual 8086 mode flag) | 标志寄存器的第17位,当其被设置表示启用虚拟8086模式(在保护模式下模拟实模式),否则退回到保护模式工作。 | 系统标志 | |
| AC | 对齐检查标志(Alignment check (or access control) flag) | 标志寄存器的第18位。当该标志位被设置且CR0寄存器中的AM位被设置时,将对用户态下对内存引用进行对齐检查,在存在未对齐的操作数时产生异常。 | 系统标志 | |
| VIF | 虚拟中断标志(Virtual interrupt flag) | 标志寄存器的第19位,为IF标志的虚拟映象。该标志与VIP标志一起,且在CR4寄存器中VME或PVI位被设置且IOPL小于3时,处理器才将识别该标志。 | 系统标志 | |
| VIP | 虚拟中断挂起标志(Virtual interrupt pending flag) | 标志寄存器的第20位,其被设置表示有一个中断被挂起(等待处理),否则表示没有等待处理的中断。该标志通常与VIF标志搭配一起使用。 | 系统标志 | |
| ID | ID标志(Identification flag) | 标志寄存器的第21位,通过修改该位的值可以测试是否支持CPUID指令。 | 系统标志 |
指令对标志位的影响¶
| 指令 | 影响说明 |
|---|---|
| add | OE、 SF、 ZE、 AF、 CF 和 PE 的状态依计算结果而定。 |
| cbw | 不影响任何标志位。 |
| cld | DF=0, CE、 OE、ZF、SE、AF 和 PF 未定义。未定义的意思是到目前为止还不打算让该指令影响到这些标志,因此,不要在程序中依赖这些标志。 |
| cwd | 不影响任何标志位。 |
| dec | CF标志不受影响,因为该指令通常在程序中用于循环计数,而且在循环体内通常有依赖CF 标志的指令,故不希望它打扰 CF 标志;对 OE、SF、 ZE、 AF 和 PE 的影响依计算结果而定。 |
| div/idiv | 对 CE、 OF、SE、ZE、AF 和 PF 的影响未定义。 |
| inc | CE 标志不受影响,对 OE、SE、ZE、AF 和 PF 的影响依计算结果而定。 |
| mov / movs | 这类指令不影响任何标志位。 |
| neg | 如果操作数为0,则CF=0,否则 CE=1;对OF、SE、ZE、AF 和 PF 的影响依计算结果而定。 |
| std | DE=1,不影响其他标志位。 |
| sub | 对 OF、SE、ZE、AE、PF 和 CF 的影响依计算结果而定。 |
| xor | OF=0, CE=0;对SE、ZF 和 PE 依计算结果而定;对AF 的影响未定义。 |
| cmp | cmp指令仅仅根据两个操作数相减的结果设置相应的标志位,而不保留计算结果,因此也就不会改变两个操作数的原有内容。cmp指令将会影响到CF、OF、SF、ZF、AF和PF标志位。 |
| or | or指令对标志寄存器的影响是:OF和CF位被清零,SF、ZF、PF位的状态依计算结果而定,AF位的状态未定义。 |
条件转移指令¶
| 指令 | 英文描述 | 比较结果 | 相关标志位的状态 |
|---|---|---|---|
| je | Equal | 等于 | 相减结果为零才成立,故要求 ZF=1 |
| jne | Not Equal | 不等于 | 相减结果不为零才成立,故要求 ZF=0 |
| jg | Greater | 大于 | 适用于有符号数比较。 要求:ZF=0(两个数不同,相减的结果不为Q),并且 SF=OF(如果相减后溢出,则结果必须是负数,说明目的操作数大:如果相减后未溢出,则结果必须是正数,也表明目的操作数大些) |
| jge | Greater or Equal | 大于或等于 | 适用于有符号数的比较。 要求:SF=OF |
| jng | Not Greater | 不大于 | 适用于有符号数的比较。 要求:ZF=1(两个数相同,相减的结果为0),或者 SF+OF(如果相减后溢出,则结果必须是正数,说明源操作数大:如果相减后未溢出,则结果必须是负数,同样表明源操作数大些) |
| jnge | Not Greater or Equal | 不大于或等于 | 适用于有符号数的比较。 要求:SF≠OF |
| jl | Less | 小于 | 适用于有符号数的比较,等同于“不大于或等于” 要求:SF≠OF |
| jle | Less or Equal | 小于或等于 | 适用于有符号数的比较,等同于“不大于” 要求:ZF=1(两个数相同,相减的结果为0),并且SF≠OF(如果相减后溢出,则结果必须是正数,说明源操作数大:如果相减后未溢出,则结果必须是负数,同样表明源操作数大些) |
| jnl | Not Less | 不小于 | 适用于有符号数的比较,等同于“大于或等于” 要求:SF=OF |
| jnle | Not Less or Equal | 不小于或等于 | 适用于有符号数的比较,等同于“大于” 要求:ZF=0(两个数不同,相减的结果不为0),并且 SF=OF (如果相减后溢出,则结果必须是负数,说明目的操作数大;如果相减后未溢出,则结果必须是正数,也表明目的操作数大些) |
| ja | Above | 高于 | 适用于无符号数的比较 要求:CF=0(没有进位或借位)而且 ZF=0(两个数不相同) |
| jae | Above or Equal | 高于或等于 | 适用于无符号数的比较 要求:CF=0(目的操作数大些,不需要借位) |
| jna | Not Above | 不高于 | 适用于无符号数的比较,等同于“低于或等于”(见后) 要求:CF=1 或者 ZF=1 |
| jnae | 不高于或等于 | Not Above or Equal | 适用于无符号数的比较,等同于“低于”(见后) 要求:CF=1 |
| jb | Below | 低于 | 适用于无符号数的比较 要求:CF=1 |
| jbe | Below or Equal | 低于或等于 | 适用于无符号数的比较 要求:CF=1 或者 ZF=1 |
| jnb | Not Below | 不低于 | 适用于无符号数的比较,等同于“高于或等于” 要求:CF=0 |
| jnbe | Not Below or Equal | 不低于或等于 | 适用于无符号数的比较,等同于“高于” 要求:CF=0 而且 ZF=0 |
| jpe | Parity Even | 校验为偶 | 要求:PF=1 |
| jpo | Parity Odd | 检验为奇 | 要求:PF=0 |
| jcxz | jump if CX is zero | 当寄存器CX的内容为零时,则进行跳转 | 要求:当寄存器CX的内容为零时,则进行跳转 |
| jz | jump if zero | 如果为0,则跳转。当cmp指令一起使用时,等同于jz | |
| jnz | jump if no zero | 如果不为0,则跳转,当和cmp指令一起使用时,等同于jne |
NASM编译器的\(和\)$标记¶
$是当前位置的汇编地址;$$是NASM编译器提供的另一个标记,代表当前汇编节(段)的起始汇编地址。当前程序没有定义节或段,就默认地自成一个汇编段,而且起始的汇编地址是0(程序起始处)。
下面几种无限循环是等效的:
Chap8: 比高斯更快的计算¶
累加和各个数位的分解与显示¶
栈和栈段的初始化¶
栈(Stack)是一种特殊的数据存储结构,数据的存取只能从一端进行。这样,最先进去的数据只能最后出来,最后进去的数据倒是最先出来,这称为后进先出(Last In First Out, LIFO)。
和代码段、数据段和附加段一样,栈也被定义成一个内存段,叫栈段(Stack Segment),由段寄存器SS指向。
针对栈的操作有两种,分别是将数据推进栈(push)和从栈中弹出数据(pop)。简单地说,就是压栈和出栈。压栈和出栈只能在一端进行,所以需要用栈指针寄存器SP(Stack Pointer)来指示下一个数据应当压入栈内的什么位置,或者数据从哪里出栈。
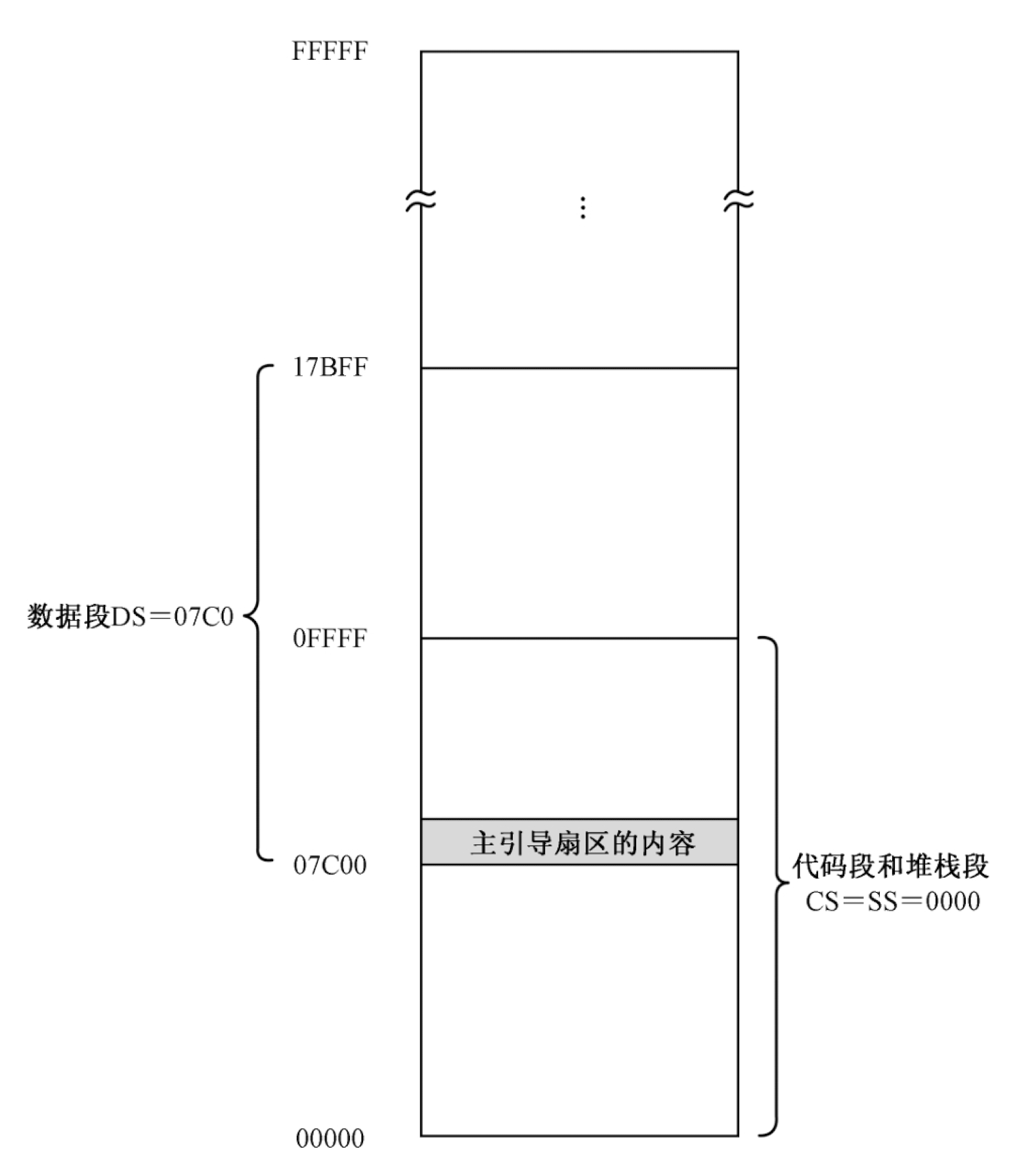
定义栈需要两个连续的步骤,即初始化段寄存器SS和栈指针SP的内容。如下8086代码中设置段基址:
mov ax, 0x7c0; 设置数据段的段基地址
mov ds, ax
mov ax, 0xb800; 设置附加段基址到显示缓冲区
mov es, ax
xor cx,cx
mov ss,cx; 设置栈段寄存器机制
mov sp,cx
上面代码设置段基址后的内存布局如下图所示,虽然代码段和栈段在本质上指向同一块内存区域,但是不要担心,主引导程序只占据着中间的一小部分,不要两者不要覆盖就行了。
进一步认识栈¶
引入栈和push、pop指令只是为了方便程序开发。临时保存一个数值到栈中,使用push指令是最简洁、最省事的,但如果不怕麻烦,可以不使用它。所以,下面的代码可以用来取代push ax指令:
同样,pop ax指令的执行结果和下面的代码相同:
8086处理器的寻址方式¶
处理器的一生,是忙碌的一生,只要它工作着,就必定是在取指令和执行指令。它就像勤劳的牛,吃的是电,挤出来的还是电,不过是另一种形式的电。
既然操作和处理的是数值,那么,必定涉及数值从哪里来,处理后送到哪里去,这称为 寻址方式(Addressing Mode)。简单地说,寻址方式就是如何找到要操作的数据,以及如何找到存放操作结果的地方。
寄存器寻址¶
立即寻址¶
内存寻址¶
我们知道,8086处理器访问内存时,采用的是段地址左移4位,然后加上偏移地址,来形成20位物理地址的模式,段地址由4个段寄存器之一来提供,偏移地址要由指令来提供。
所谓的内存寻址方式,就是如何在指令中指定操作数的偏移地址,供处理器访问内存时使用,这个偏移地址也叫 有效地址(Effective Address, EA)。换句话说,内存寻址方式就是在指令中指定偏移地址(有效地址)如何计算。
直接寻址¶
基址寻址¶
变址寻址¶
基址变址寻址¶
Chap9:硬盘和显卡的访问与控制¶
程序通常是分段的,载入内存之后,还要重新计算段地址,这叫作 段的重定位。
用户程序的结构¶
分段、段的汇编地址和段内汇编地址¶
INTEL 8086处理器的工作模式是将内存分成逻辑上的段,指令的获取和数据的访问一律按“段地址:偏移地址”的方式进行。相对应的,一个规范的程序,应当包括代码段、数据段、附加段和栈段。
NASM编译器使用汇编指令“SECTION”或者“SEGMENT”来定义段。它的一般格式是:
注意: 1. 段名称可以是任意名字,只要它们彼此之间不会重复和混淆。 2. 一旦定义段,那么,后面的内容就都属于该段,除非又出现了另一个段的定义。如果整个程序中都没有段定义语句。这时,整个程序自成一个段。 3. NASM对段的数量没有限制。 4. INTEL处理器要求段在内存中的起始物理地址起码是16字节对齐的,或者说必须是16的倍数,能被16整除。编写程序时定义的段迟早要加载到内存中,成为内存中的段,所以在编写源程序时定义的段也必须至少按16字节对齐。 5. 要在编写程序时指定段的对齐方式,应该使用“align=”子句,并指定一个具体的对齐。比如说,“align=16”就表示段是16字节对齐的,“align=32”就表示段是32字节对齐的。
在程序编译后,每个段都位于二进制文件的特定位置,这个位置可以用它相对于文件起始处的距离来衡量,这就是 段的汇编地址。段的汇编地址是段的起始位置,它也是段内第一字节的汇编地址。
- 为了将一个段对齐于特定的汇编地址,可能需要在它前面的那个段内填充数据。
- 最后一个段地址不需要填充数据
- 为了方便取得该段的汇编地址,NASM编译器提供了
section.段名.start的表达式l来获取 - 段定义语句可以包含“vstart=”子句,那么引用某个标签时,该标签处的汇编地址是从段的开头处计算的,而不是从整个程序的开头计算的
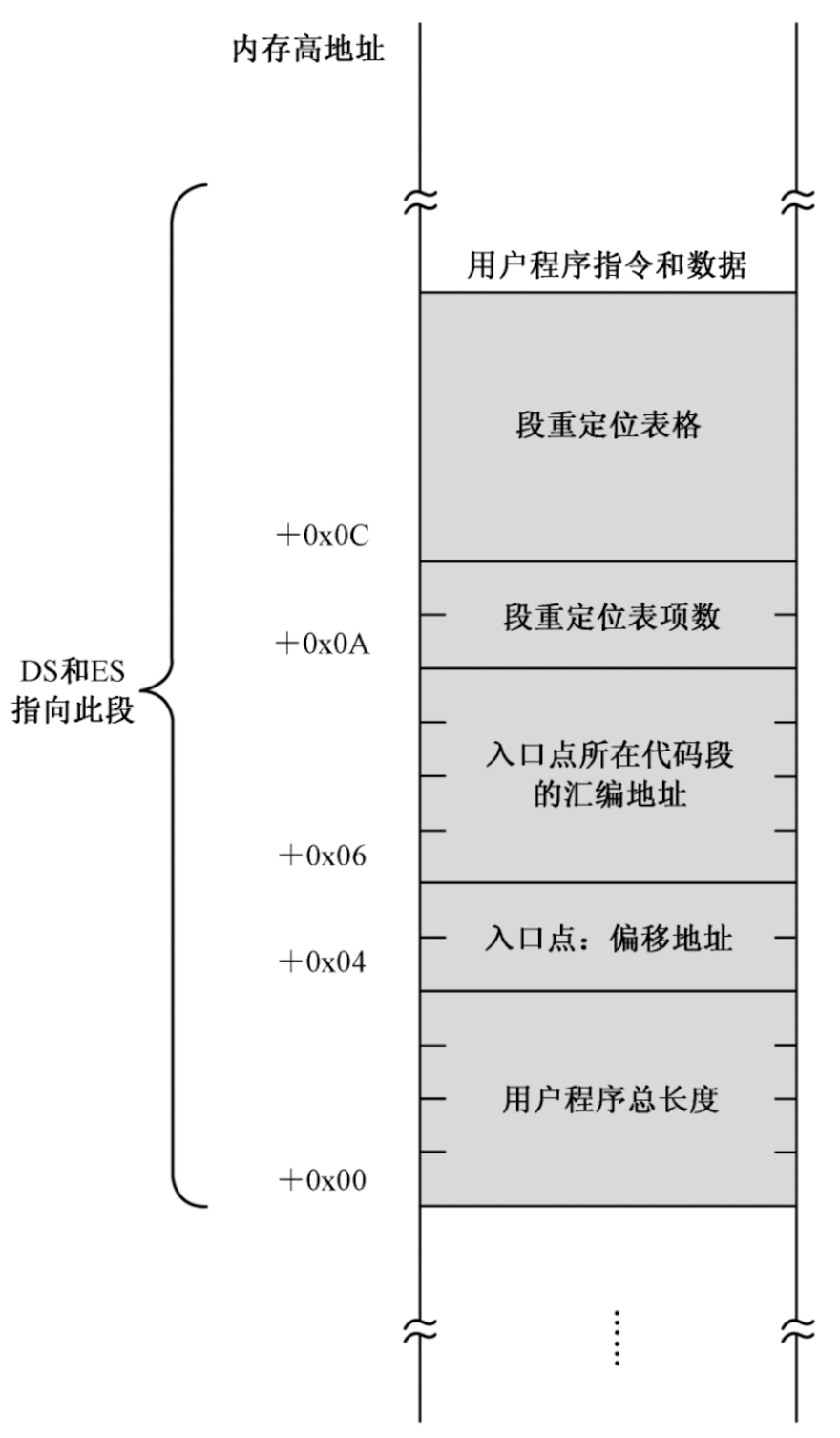
用户程序头部¶
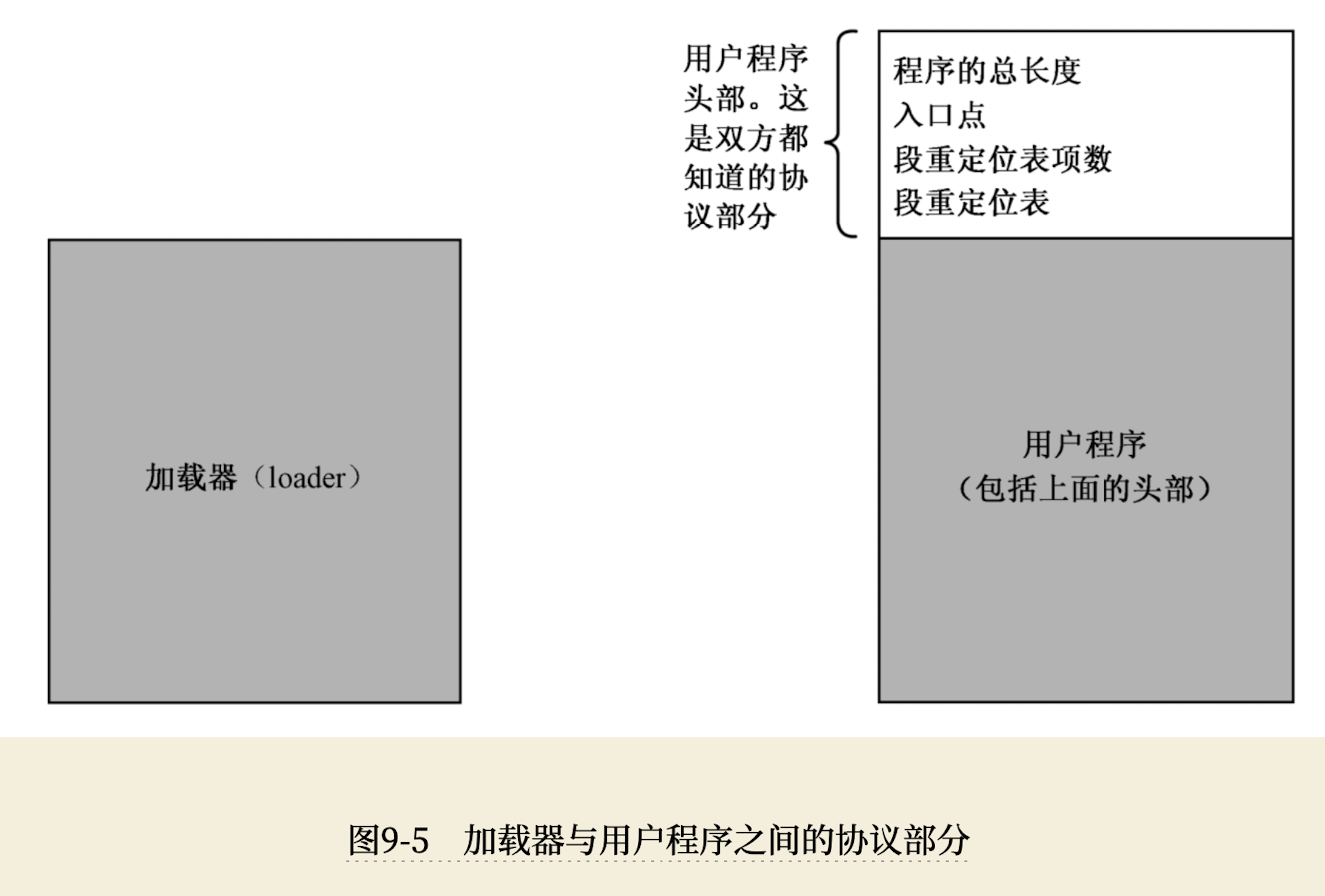
加载器依赖应用程序的头部信息,头部信息一般要包含以下信息:
- 用户程序的尺寸,即以字节为单位的大小。
- 应用程序的入口点,包括段地址和偏移地址。这就是所谓的应用程序入口点(Entry Point)。
- 段重定位表。程序加载到内存后,每个段的地址必须重新确定一下。
- 段的重定位是加载器的工作,它需要知道每个段在用户程序内的位置,即它们分别位于用户程序内的多少字节处。为此,需要在用户程序头部建立一张段重定位表。
加载程序(器)的工作流程¶
初始化和决定加载位置¶
常数是用伪指令equ声明的,它的意思是“等于”。用equ声明的数值不占用任何汇编地址,也不在运行时占用任何内存位置。它仅仅代表一个数值,就这么简单。
加载器的内存布局如下图:
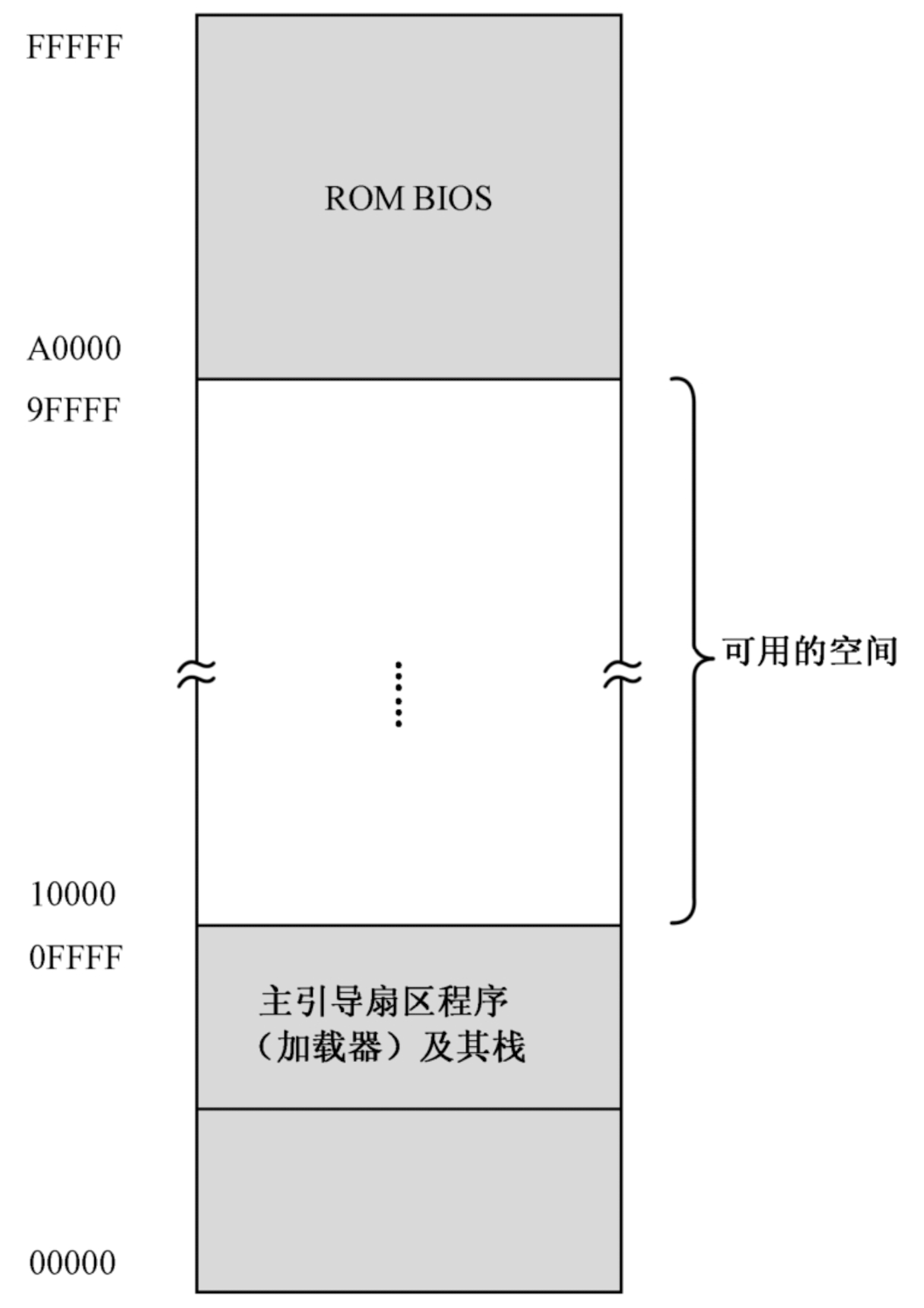
如上图所示:
- 物理地址0x0FFFF以下,是加载器及其栈的势力范围。
- 物理地址A0000以上,是BIOS和外围设备的势力范围,有很多传统的老式设备将自己的存储器和只读存储器映射到这个空间。
- 可用的空间就位于0x10000~9FFFF,差不多500多KB。
外围设备及其接口¶
所有这些和处理器打交道的设备叫作 外围设备(Peripheral Equipment),都围绕在处理器周围,争着跟它说话。
不同的外围设备,都有各自不同的I/O接口。I/O接口用于与处理器打交道。I/O接口可以是一个电路板,也可能是一块小芯片,这取决于它有多复杂。无论如何,它是一个典型的变换器,或者说是一个翻译器,在一边,它按处理器的信号规程工作,负责把处理器的信号转换成外围设备能接受的另一种信号;在另一边,它也做同样的工作,把外围设备的信号变换成处理器可以接受的形式。
这还没完,后面还有两个麻烦的问题。 1. 不可能将所有的I/O接口直接和处理器相连,设备那么多,还有些设备现在没有发明出来,将来一定会有。你怎么办? 2. 每个设备的I/O接口都抢着和处理器说话,不发生冲突都难。你怎么办?
对第1个问题的解答是采用总线技术。总线可以认为是一排电线,所有的外围设备,包括处理器,都连接到这排电线上。但是,每个连接到这排电线上的器件都必须拥有电子开关,以使它们随时能够同这排电线连接,或者从这排电线上断开(脱离)。这就好比是公共车道,当路面上有车时,你就必须退避一下,不能硬冲上去。因此,这排公共电线就称为 总线(Bus)。
对第2个问题的解答是使用输入输出控制设备集中器(I/O Controller Hub, ICH)芯片,该芯片的作用是连接不同的总线,并协调各个I/O接口对处理器的访问。在个人计算机上,这块芯片就是所谓的南桥。
如下图所示,处理器通过局部总线连接到ICH内部的处理接口电路。然后,在ICH内部,又通过总线与各个I/O接口相连。
在ICH内部,集成了一些常规的外围设备接口,如USB、PATA(IDE)、SATA、老式总线接口(LPC)、时钟等,这些东西对计算机来说必不可少,故直接集成在ICH内。
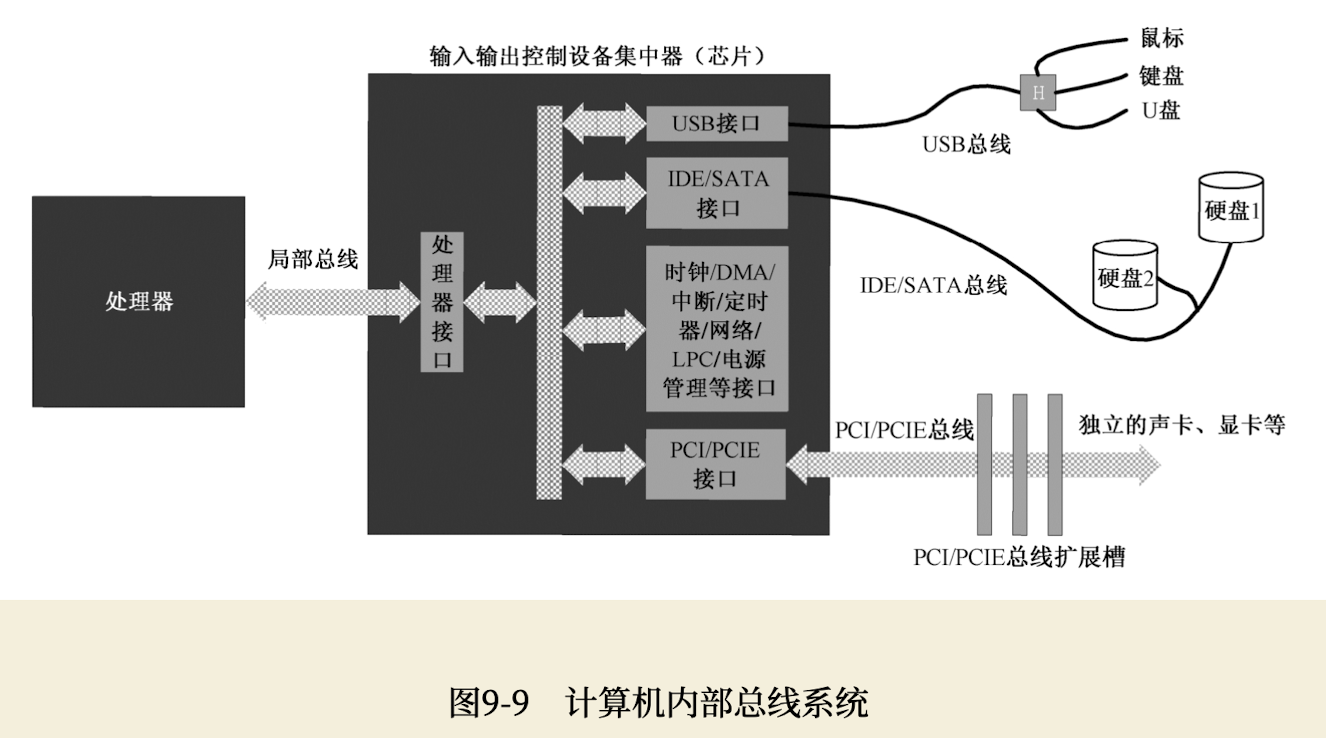
不管是什么设备,都必须通过它自己的I/O接口电路同ICH相连。为了方便,最好是在主板上做一些插槽,同时,每个设备的I/O接口电路都设计成插卡。这样,想接上该设备时,就把它的I/O接口卡插上,不需要时,随时拔下。
为了实现这个目的,或者说为了支持更多的设备,ICH还提供了对PCI或者PCI Express总线的支持,该总线向外延伸,连接着主板上的若干个扩展槽,就是刚才说的插槽。举个实例,如果你想连接显示器,那么就要先插入显卡,然后再把显示器接到显卡上。
除了局部总线和PCI Express总线,每个I/O接口卡可能连接不止一个设备。比如USB接口,就有可能连接一大堆东西:键盘、鼠标、U盘等。因为同类型的设备较多,也涉及线路复用和仲裁的问题,故它们也有自己的总线体系,称为通信总线或者设备总线。比如上图所示的USB总线和IDE/SATA总线。
当处理器想同某个设备说话时,ICH会接到通知。然后,它负责提供相应的传输通道和其他辅助支持,并命令所有其他无关设备闭嘴。同样,当某个设备要跟处理器说话,情况也是一样的。
I/O端口和端口访问¶
外围设备和处理器之间的通信是通过相应的I/O接口进行的。具体地说,处理器是通过端口(Port)来和外围设备打交道的。本质上,端口就是一些寄存器,类似于处理器内部的寄存器。不同之处仅仅在于,这些叫作端口的寄存器位于I/O接口电路中。
端口是处理器和外围设备通过I/O接口交流的窗口,每个I/O接口都可能拥有好几个端口,分别用于不同的目的。比如,连接硬盘的PATA/SATA接口就有几个端口,分别是命令端口(当向该端口写入0x20时,表明是从硬盘读数据;写入0x30时,表明是向硬盘写数据)、状态端口(处理器根据这个端口的数据来判断硬盘工作是否正常,操作是否成功,发生了哪种错误)、参数端口(处理器通过这些端口告诉硬盘读写的扇区数量,以及起始的逻辑扇区号)和数据端口(通过这个端口连续地取得要读出的数据,或者通过这个端口连续地发送要写入硬盘的数据)。
端口只不过是位于I/O接口上的寄存器,所以,每个端口有自己的数据宽度。在早期的系统中,端口可以是8位的,也可以是16位的,现在有些端口会是32位的。到底是8位还是16位,这是设备和I/O接口制造者的自由。比如,PATA/STAT接口中的数据端口就是16位的,这有助于加快数据传输速率,提高传输效率。
端口在不同的计算机系统中有着不同的实现方式。在一些计算机系统中,端口号是映射到内存地址空间的。比如,0x00000~0xE0000是真实的物理内存地址,而0xE0001~0xFFFFF是从很多I/O接口那里映射过来的,当访问这部分地址时,实际上是在访问I/O接口。
而在另一些计算机系统中,端口是独立编址的,不和内存发生关系。如下图所示,在这种计算机中,处理器的地址线既连接内存,也连接每个I/O接口。但是,处理器还有一个特殊的引脚M/IO#,在这里,“#”表示低电平有效。也就是说,当处理器访问内存时,它会让M/IO#引脚呈高电平,这里,和内存相关的电路就会打开;相反,如果处理器访问I/O端口,那么M/IO#引脚呈低电平,内存电路被禁止。与此同时,处理器发出的地址和M/IO#信号一起用于打个某个I/O接口,如果该I/O接口分配的端口号与处理器地址相吻合的话。
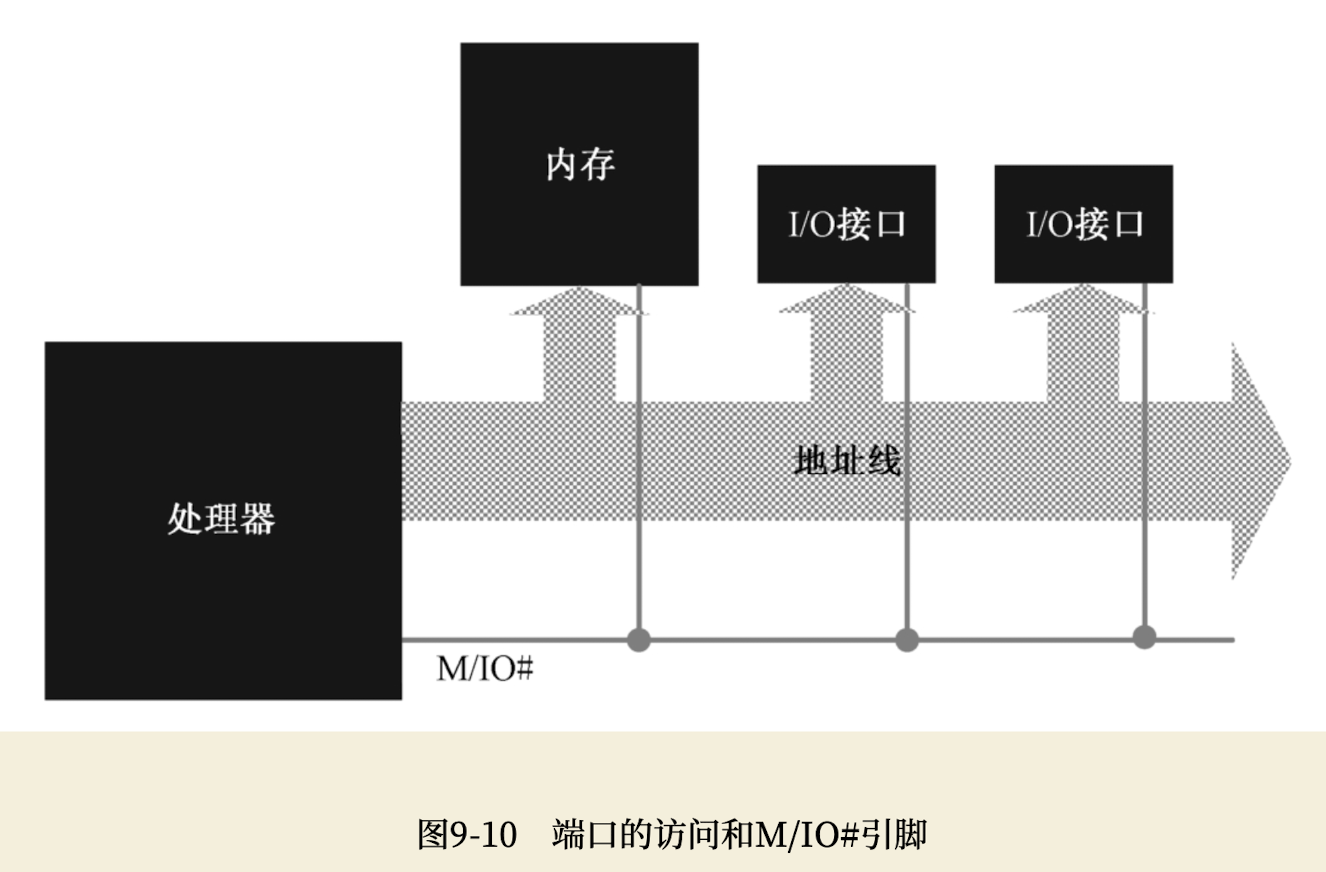
INTEL处理器,早期是独立编址的,现在既有内存映射的,也有独立编址的。所有端口都是统一编号的。
一个现实的例子是个人计算机中的PATA/SATA接口,每个PATA和SATA接口分配了8个端口。但是,ICH芯片内部通常集成了两个PATA/SATA接口,分别是主硬盘接口和副硬盘接口。这样一来,主硬盘接口分配的端口号是0x1f0~0x1f7,副硬盘接口分配的端口号是0x170~0x177。
在INTEL的系统中,只允许65536(十进制数)个端口存在,端口号从0到65535(0x0000~0xffff)。因为是独立编址,所以,端口的访问不能使用类似于mov这样的指令,取而代之的是in和out指令。
in指令是从端口读,它的一般形式是:
这就是说,in指令的目的操作数必须是寄存器AL或者AX,当访问8位的端口时,使用寄存器AL;访问16位的端口时,使用AX。in指令的源操作数应当是寄存器DX,用来指定端口号。
in al,dx的机器指令码是0xEC,in ax,dx的机器指令码是0xED,都是一字节的。之所以如此简短,是因为in指令不允许使用别的通用寄存器,也不允许使用内存地址作为操作数。
in指令还有2字节的形式。此时,前一字节是操作码0xE4或者0xE5,分别用于指示8位或者16位端口访问;后一字节是立即数,指示端口号。
因此,机器指令E4 F0就相当于汇编语言指令:
而机器指令E5 03就相当于汇编语言指令:
很显然,因为这种指令形式的源操作数部分只允许一字节,故只能访问0~255(0x00~0xff)号端口,不允许访问大于255的端口号。
相应的,如果要通过端口向外围设备发送数据,则必须通过out指令。
out指令正好和in指令相反,目的操作数可以是8位立即数或者寄存器DX,源操作数必须是寄存器AL或者AX。
out 0x37, al ;写0x37号端口(这是一个8位端口)
out 0×f5, ax ;写0×x£5号端口(这是一个16 位端口)
out dx, al ;这是一个8位端口,端口号在寄存器DX中
out dx, ax ;这是一个16 位端口,端口号在寄存器 Dx中
通过硬盘控制器端口读扇区数据¶
笔者注:
- 本章节介绍的是 ATA PIO Mode。根据 ATA 规范,所有 ATA 兼容驱动器必须始终支持 PIO 模式作为默认数据传输机制。 PIO 模式使用大量的 CPU 资源,因为磁盘和 CPU 之间传输的每个字节的数据都必须通过 CPU 的 IO 端口总线(而不是内存)发送。在某些CPU上,PIO模式仍然可以达到每秒16MB的实际传输速度,但机器上的其他进程不会获得任何CPU时间。然而,当计算机刚刚开始启动时,没有其他进程。因此,PIO 模式是一个优秀且简单的界面,可以在启动期间使用,直到系统进入多任务模式。
- 本章节介绍的是ATA硬盘的读写,ATA之后是SATA硬盘,为了与SATA进行区分,ATA更忙为PATA。参见Writing a Simple Operating System读写硬盘(ATA PIO模式)
硬盘读写的基本单位是扇区。就是说,要读就至少读一个扇区,要写就至少写一个扇区,不可能仅读写一个扇区中的几个字节。这样一来,就使得主机和硬盘之间的数据交换是成块的,所以硬盘是典型的块设备。
从硬盘读写数据,最经典的方式是向硬盘控制器分别发送磁头号、柱面号和扇区号(扇区在某个柱面上的编号),这称为 CHS模式。这种方法最原始,最自然,也最容易理解。
实际上,在很多时候,我们并不关心扇区的物理位置,所以希望所有的扇区都能统一编址。这就是逻辑扇区。逻辑扇区从0开始编号。
最早的逻辑扇区编址方法是LBA28,使用28比特来表示逻辑扇区号,从逻辑扇区0x0000000到0xFFFFFFF,共可以表示228=268435456个扇区。每个扇区有512字节,所以LBA28可以管理128 GB的硬盘。
硬盘技术发展得非常快,最新的硬盘已经达到几百GB的容量,LBA28已经落后了。在这种情况下,业界又共同推出了LBA48,采用48比特来表示逻辑扇区号。如此一来,就可以管理131072 TB的硬盘容量了。
个人计算机上的主硬盘控制器被分配了8位端口,端口号从0x1f0到0x1f7。假设现在要从硬盘上读逻辑扇区,那么,整个过程如下:
- 第1步,设置要读取的扇区数量。这个数值要写入0x1f2端口。这是个8位端口,因此每次只能读写255个扇区:
注意,如果写入的值为0,则表示要读取256个扇区。每读一个扇区,这个数值就减1。因此,如果在读写过程中发生错误,该端口包含着尚未读取的扇区数。
- 第2步,设置起始LBA扇区号。扇区的读写是连续的,因此只需要给出第一个扇区的编号就可以了。28位的扇区号太长,需要将其分成4段,分别写入端口0x1f3、0x1f4、0x1f5和0x1f6。其中,0x1f3号端口存放的是0~7位;0x1f4号端口存放的是8~15位;0x1f5号端口存放的是16~23位,最后4位在0x1f6号端口。假定我们要读写的起始逻辑扇区号为0x02,可编写代码如下:
mov dx, 0x1f3
mov al, Ox02
out dx, al ;LBA 地址7~0
inc dx; 0x1£4
mov al, 0x00
out dx, al ;LBA 地址15~8
inc dx ;0x1f5
out dx, al ;LBA 地址 23~16
inc dx ; 0x1f6
mov al, 0xe0 ;LBA 模式,主硬盘,以及LBA 地址27~24
out dx, al
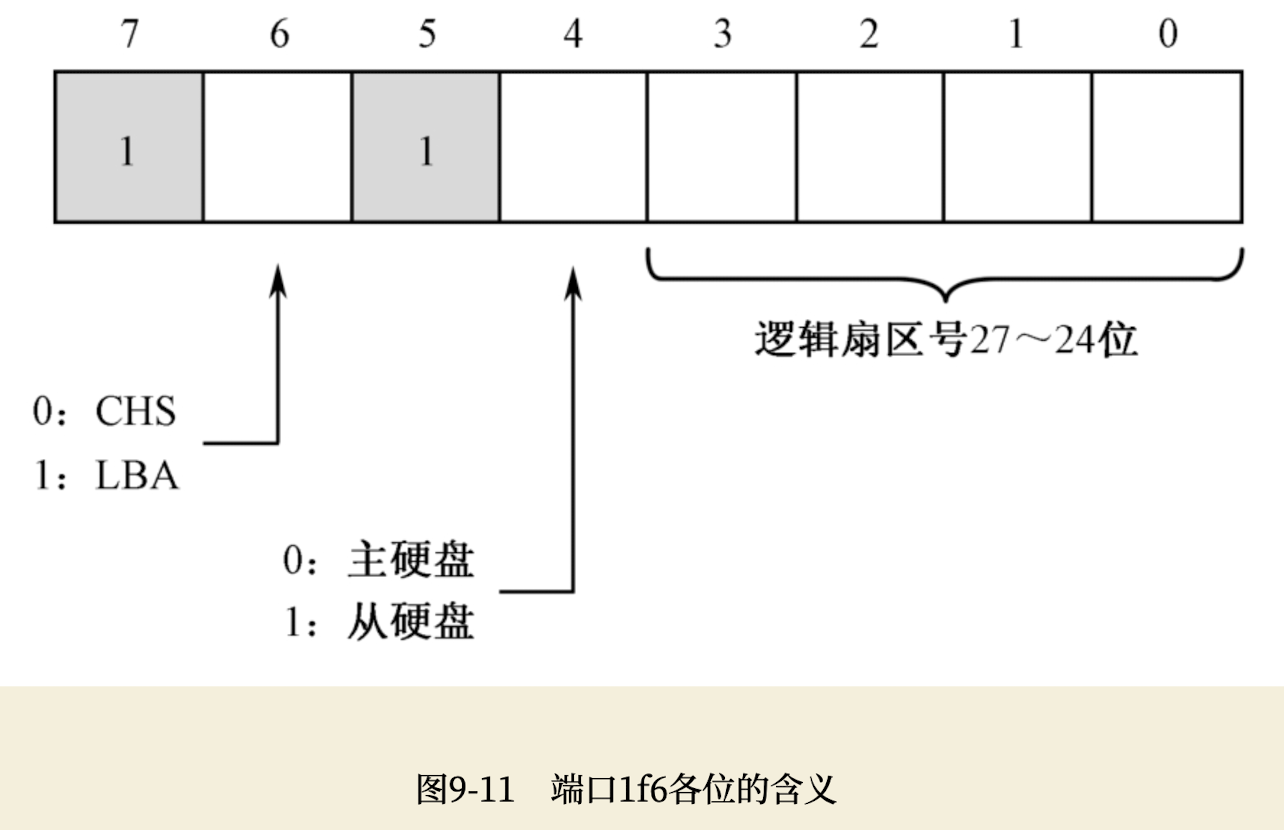
注意以上代码的最后4行,在现行的体系下,每个PATA/SATA接口允许挂接两块硬盘,分别是主盘(Master)和从盘(Slave)。如下图所示,0x1f6端口的低4位用于存放逻辑扇区号的24~27位,第4位用于指示硬盘号,0表示主盘,1表示从盘。高3位是“111”,表示LBA模式。
- 第3步,向端口0x1f7写入0x20,请求硬盘读。这也是一个8位端口:
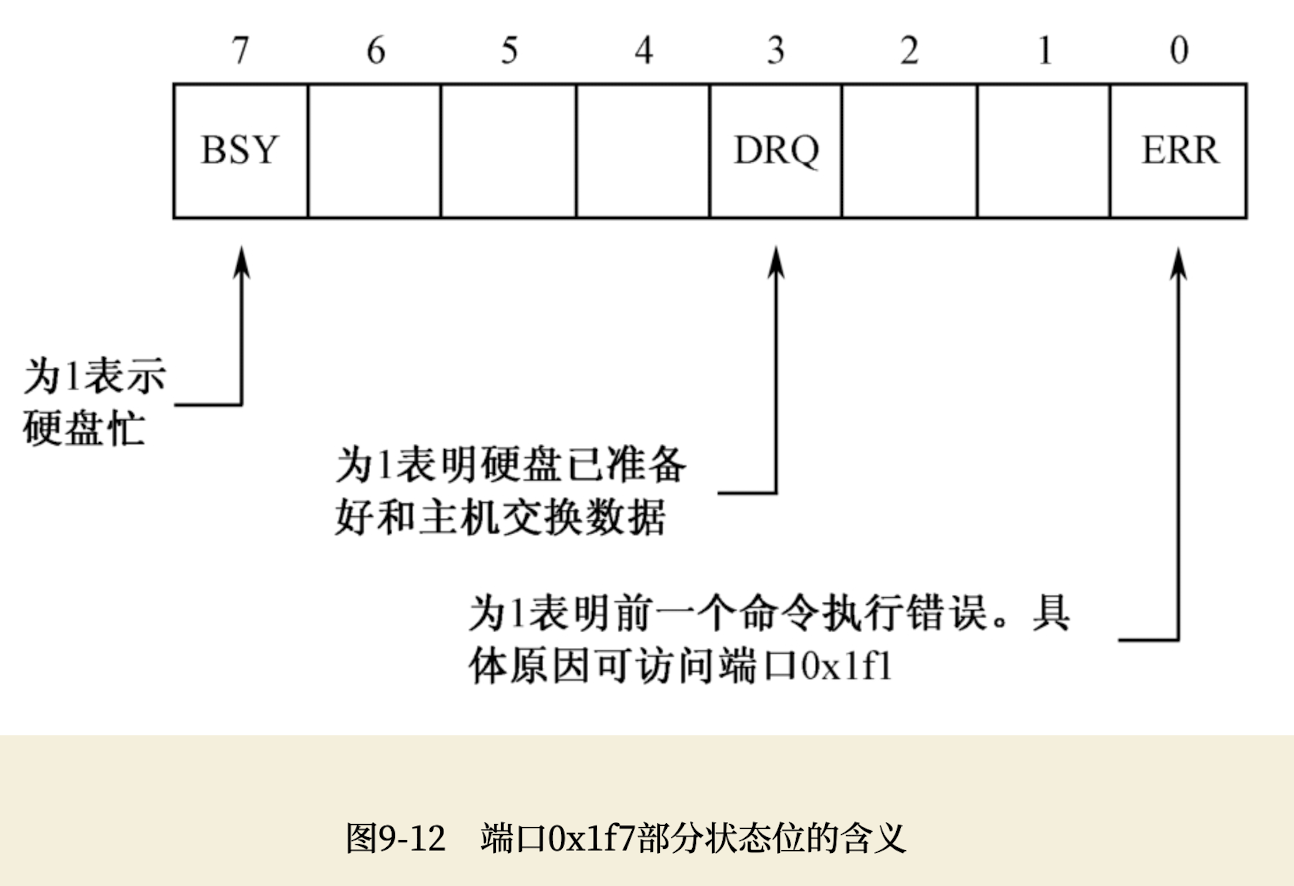
- 第4步,等待读写操作完成。端口0x1f7既是命令端口,又是状态端口。在通过这个端口发送读写命令之后,硬盘就忙乎开了。如下图所示,在它内部操作期间,它将0x1f7端口的第7位置“1”,表明自己很忙。一旦硬盘系统准备就绪,它再将此位清零,说明自己已经忙完了,同时将第3位置“1”,意思是准备好了,请求主机发送或者接收数据。完成这一步的典型代码如下:
- 第5步,连续取出数据。0x1f0是硬盘接口的数据端口,而且还是一个16位端口。一旦硬盘控制器空闲,且准备就绪,就可以连续从这个端口写入或者读取数据。
下面的代码假定是从硬盘读一个扇区(512字节,或者256字节),读取的数据存放到由段寄存器DS指定的数据段,偏移地址由寄存器BX指定:
最后,0x1f1端口是错误寄存器,包含硬盘驱动器最后一次执行命令后的状态(错误原因)。过程调用¶
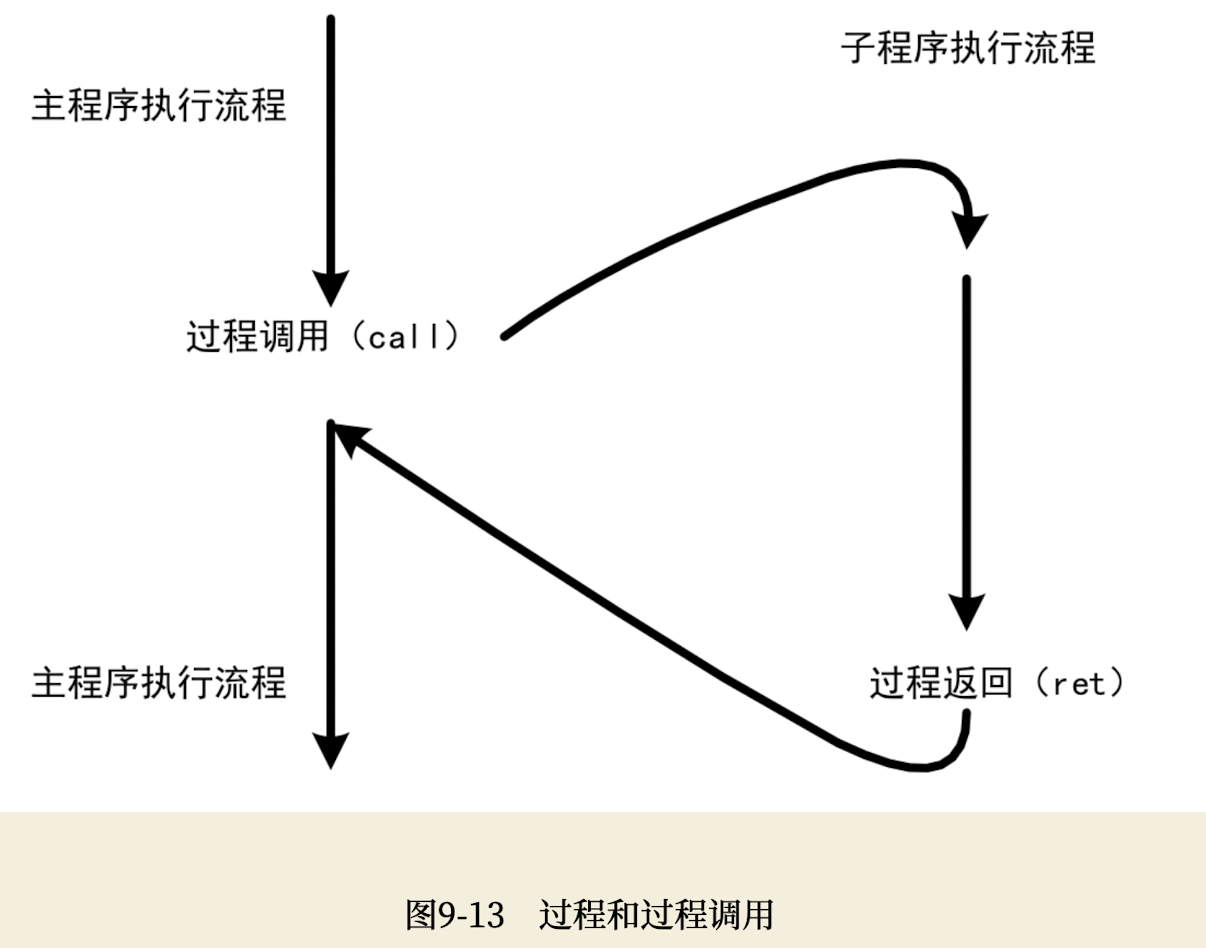
好在处理器支持一种叫过程调用的指令执行机制。过程(Procedure)又叫例程,或者子程序、子过程、子例程(Sub-routine),不管怎么称呼,实质都一样,都是一段普通的代码。处理器可以用过程调用指令转移到这段代码执行,在遇到过程返回指令时重新返回到调用处的下一条指令接着执行。
如下图所示,这是过程和过程调用的示意图。
过程调用的四种调用方式¶
调用过程的指令是“call”。8086处理器支持四种调用方式。
16位相对近调用¶
近调用的意思是被调用的目标过程位于当前代码段内,而非另一个不同的代码段,所以只需要得到偏移地址即可。
16位相对近调用是三字节指令,操作码为0xE8,后跟16位有符号的操作数(换句话说,被调用过程的首地址必须位于距离当前call指令-32768~32767字节的地方),因为是相对调用,故该操作数是当前call指令相对于目标过程的偏移量。计算过程如下:用目标过程的汇编地址减去当前call指令的下一条指令的汇编地址,保留16位的结果。
当前call指令的下一条指令的汇编地址可以用当前call指令的地址加上3个字节得到,因为call near指令为0xE8占用一个字节,后面的操作数占用2个字节。
关键字“near”不是必需的,如果call指令中没有提供任何关键字,则编译器认为该指令是近调用。下面两条指令是相同的:
在指令执行阶段,处理器看到操作码0xE8,就知道它应当调用一个过程。于是,它用指令指针寄存器IP的当前内容(它已经指向下一条指令)加上指令中的操作数,得到一个新的偏移地址。接着,将指令指针寄存器IP的原有内容压入栈。最后,用刚才计算出的偏移地址取代指令指针寄存器IP原有的内容。这直接导致处理器的执行流转移到目标位置处。
16位间接绝对近调用¶
这种调用也是近调用,只能调用当前代码段内的过程,指令中的操作数不是偏移量,而是被调用过程的真实偏移地址,故称为 绝对地址。不过,这个偏移地址不是直接出现在指令中的,而是由16位的通用寄存器或者16位的内存单元间接给出的。比如:
call cx ;目标地址在 cx中。省略了关键字 “near”,下同
call [Ox3000] ;要先访问内存才能取得目标偏移地址
call [bx] ;要先访问内存才能取得目标偏移地址
call [bx + si + 0x021] ;要先访问内存才能取得目标偏移地址
以上,第一条指令的机器码为FF D1,被调用过程的偏移地址位于寄存器CX内,在指令执行的时候由处理器从该寄存器取得,并直接取代指令指针寄存器IP原有的内容。
第二条指令的机器码为FF 16 00 30。当这条指令执行时,处理器访问数据段(使用段寄存器DS),从偏移地址0x3000处取得一个字,作为目标过程的真实偏移地址,并用它取代指令指针寄存器IP原有的内容。 后面两条指令没什么好说的,只是寻址方式不同而已。
间接绝对近调用指令在执行时,处理器首先按以上的方法计算被调用过程的偏移地址,然后将指令指针寄存器IP的当前值压栈,最后用计算出来的偏移地址取代寄存器IP原有的内容。
16位直接绝对远调用¶
这种调用属于段间调用,即调用另一个代码段内的过程,所以称为远调用(far call)。很容易想到,远调用既需要被调用过程所在的段地址,也需要该过程在段内的偏移地址。
16位间接绝对远调用¶
这也属于段间调用,被调用过程位于另一个代码段内,而且,被调用过程所在的段地址和偏移地址是间接给出的。还有,这里的“16位”同样是用来限定偏移地址的。
因为是远调用,也就是段间调用,所以,必须给出被调用过程的段地址和偏移地址。但是指令中仅仅给出的是该位置的内存偏移地址,需要读取内存的内容获取代码段地址和偏移地址。
举例说明:
proc_1标签对应的内存内容是某个过程的段地址和偏移地址。按处理器的要求,偏移地址在前,段地址在后。也就是说,0x0102是偏移地址;0x2000是段地址。
为了调用该过程,可以在代码段内使用这条指令:
当这条指令执行时,处理器访问由段寄存器DS指向的数据段,从指令中指定的偏移地址(由标号proc_1提供)处取得两个字(分别是段地址0x2000和偏移地址0x0102);接着,将代码段寄存器CS和指令指针寄存器IP的当前内容分别压栈;最后,用刚才取得的段地址和偏移地址分别取代CS和IP的原值。
返回指令ret和retf¶
ret和retf经常用作call和call far的配对指令。ret是近返回指令,当它执行时,处理器只做一件事,那就是从栈中弹出一个字到指令指针寄存器IP中。
retf是远返回指令(return far),它的工作稍微复杂一点点。当它执行时,处理器分别从栈中弹出两个字到指令指针寄存器IP和代码段寄存器CS中。
尽管call指令通常需要ret/retf和它配对,遥相呼应,但ret/retf指令却并不依赖于call指令。call指令在执行过程调用时不影响任何标志位,ret/retf指令对标志位也没有任何影响。
加载用户程序¶
第一次读硬盘将得到用户程序最开始的512字节,这512字节包括最开始的用户程序头部,以及一部分实际的指令和数据。
用户程序总长度占用4个字节,如果恰好是512个字节,商就是整个程序的所占到扇区数,否则商再加上1才是扇区数。
用户程序被加载的位置是由寄存器DS和ES所指向的逻辑段。一个逻辑段最大也才64KB,当用户程序特别大的时候,根本容纳不下。想想看,段内偏移地址从0x0000开始,一直延伸到最大值0xffff。再大的话,又绕回到0x0000,以至于把最开始加载的内容给覆盖掉了。
其实,要解决这个问题最好的办法是,每次往内存中加载一个扇区前,都重新在前面的数据尾部构造一个新的逻辑段,并把要读取的数据加载到这个新段内。如此一来,因为每个段的大小是512字节,即十六进制的0x200,右移4位(相当于除以16或者0x10)后是0x20,这就是各个段地址之间的差值。每次构造新段时,只需要在前面段地址的基础上增加0x20即可得到新段的段地址。
用户程序重定位¶
尽管DX:AX中是32位的用户程序起始物理内存地址,理论上,它只有20位,是有效的,低16位在寄存器AX中,高4位在寄存器DX的低4位。寄存器AX经右移后,高4位已经空出,只要将DX的最低4位挪到这里,就可以得到我们所需要的逻辑段地址。如下代码所示:
上面代码也可以用以下代码完成:
shr与shr指令¶
逻辑右移指令shr(SHift logical Right)用来右移处理,其用法如下:
shr r /m8,1 ;目的操作数是8位通用寄存器/内存单元,源操作数是1
shr r/m16, 1 ;目的操作数是16 位通用寄存器/内存单元,源操作数是1
shr r/m8, imm8 ;目的操作数是。位通用寄存器/内存单元,源操作数是&位立即数
shr r/ml6, imm8 ;目的操作数是16 位通用寄存器/内存单元,源操作数是8 位立即数
shr r/m8, cl ;目的操作数是8位通用寄存器/内存单元,源操作数是寄存器 CI
shr r/m16, c1;目的操作数是16位通用寄存器/内存单元,源操作数是寄存器 CL
shr ax, 4是将寄存器AX中的内容右移4位。如下图所示,逻辑右移指令执行时,会将操作数连续地向右移动指定的次数,每移动一次,“挤”出来的比特被移到标志寄存器的CF位,左边空出来的位置用比特“0”填充。
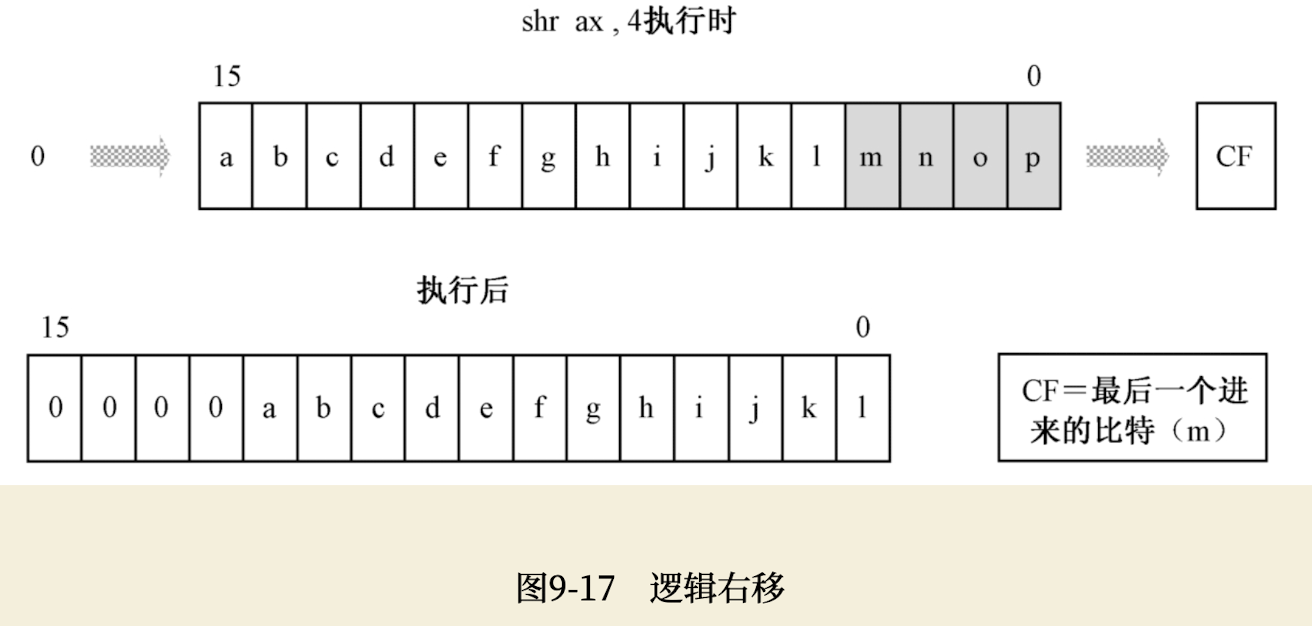
shr的配对指令是逻辑左移指令shl(SHift logical Left),它的指令格式和shr相同,只不过它是向左移动的。
逻辑右移与算术右移区别?
- 逻辑右移就是不考虑符号位,右移一位,左边补零即可
- 算术右移需要考虑符号位,右移一位,若符号位为1,就在左边补1;否则,就补0。故算术右移也可以进行有符号位的除法,右移n位就等于除2的n次方,比如下图中的-4除以4。

ror与rol指令¶
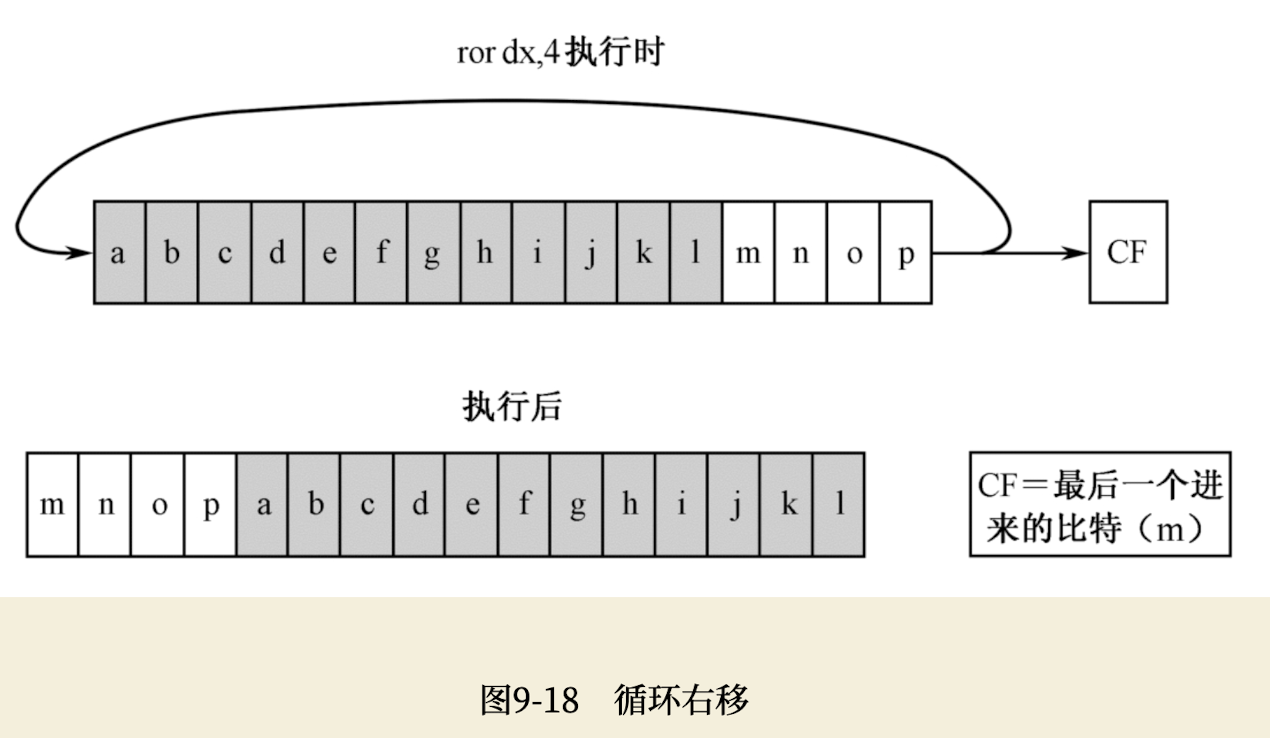
ror就是循环右移(ROtate Right),ror的配对指令是循环左移指令rol(ROtate Left)。循环右移指令执行时,每右移一次,移出的比特既送到标志寄存器的CF位,也送进左边空出的位。
将控制权交给用户程序¶
现在,用户程序已经在内存中准备就绪,剩下的工作就是把处理器的控制权交给它。交接工作很简单,代码清单9-1第76行,加载器通过一个16位的间接绝对远转移指令,跳转到用户程序入口点。处理器执行指令:
时,会访问段寄存器DS所指向的数据段,从偏移地址为0x04的地方取出两个字,并分别传送到代码段寄存器CS和指令指针寄存器IP,以替代它们原先的内容。
8086处理器的无条件转移指令¶
相对短转移¶
相对短转移的操作码为0xEB,操作数是相对于目标位置的偏移量,仅1字节,是个有符号数。由于这个原因,该指令属于段内转移指令,而且只允许转移到距离当前指令-128~127字节的地方。相对短转移指令必须使用关键字“short”。例如:
在源程序编译阶段,编译器会检查标号infinite所代表的值,如果数值超过了1字节所能允许的数值范围,则无法通过编译。否则,编译器用目标位置的汇编地址减去当前指令的下一条指令的汇编地址,保留1字节的结果,作为机器指令的操作数。
在指令执行时,处理器把指令中的操作数加到指令指针寄存器IP上,这会导致指令的执行流程转向目标地址处。
16位相对近转移¶
和相对短转移不同,16位相对近转移指令的转移范围稍大一些。它的机器指令操作码为0xE9,而且,该指令的长度为3字节,操作码0xE9后面还有一个16位(2字节)的操作数。
因为是近转移,故其属于段内转移。“相对”的意思同样是指它的操作数是一个相对量,是相对于目标位置处的偏移量。在源程序编译阶段,编译器用目标位置的汇编地址减去当前指令的下一条指令的汇编地址,保留16位的结果,作为机器指令的操作数。由于这是一个16位的有符号数,故可以转移到距离当前指令-32768~32767字节的地方。
16位相对近转移指令应当使用关键字“near”,比如:
在早先的NASM版本中,关键字near是可以省略的。若没有指定short或者near,那么,编译器自动默认是“near”的。但是最近的版本改变了这一规则。如果没有指定关键字short或者near,那么,如果目标位置距离当前指令-128~127字节,则自动采用short;否则,采用near。
16位间接绝对近转移¶
这种转移方式也是近转移,即只在段内转移。但是,转移到的目标偏移地址不是在指令中直接给出的,而是用一个16位的通用寄存器或者内存地址来间接给出的。比如:
16位直接绝对远转移¶
直接在指令中给出段地址和偏移地址的转移指令,就是直接绝对远转移指令。“16位”仅仅用来限定偏移地址部分,指偏移地址是16位的。
0x0000和0x7c00分别是段地址和偏移地址,符合“段地址:偏移地址”的表达习惯。在编译之后,其机器指令为:
0xEA是操作码,后面是操作数。注意,字的存放是按照低端字节序的。而且,在编译之后,偏移地址在前,段地址在后。执行这条指令后,处理器用指令中给出的段地址代替段寄存器CS的原有内容,用给出的偏移地址代替IP寄存器的原有内容,从而跳转到另一个不同的代码段中,即执行一个段间转移。
16位间接绝对远转移(jmp far)¶
远转移的目标地址可以通过访问内存来间接得到,这叫间接远转移,但是要使用关键字“far”。假如在某程序的数据段内声明了标号jump_far,并在其后初始化了两个字:
关键字“far”的作用是告诉编译器,该指令应当编译成一个远转移。处理器执行这条指令后,访问段寄存器DS所指向的数据段,从指令中给出的偏移地址处取出两个字,分别用来替代段寄存器CS和指令指针寄存器IP的内容。
用户程序的工作流程¶
初始化段寄存器和栈切换¶
伪指令resb(REServe Byte)¶
伪指令resb(REServe Byte)的意思是从当前位置开始,保留指定数量的字节,但不初始化它们的值。在源程序编译时,编译器会保留一段内存区域,用来存放编译后的内容。当它看到这条伪指令时,它仅仅是跳过指定数量的字节,而不管里面的原始内容是什么。
屏幕光标控制¶
光标在屏幕上的位置保存在显卡内部的两个光标寄存器中,每个寄存器是8位的,合起来形成一个16位的数值。比如,0表示光标在屏幕上第0行第0列,80表示它在第1行第0列,因为标准VGA文本模式是25行,每行80个字符。这样算来,当光标在屏幕右下角时,该值为25×80-1=1999。
光标寄存器是可读可写的。你可以从中读出光标的位置,也可以通过它设置光标的位置。
取当前光标位置¶
显卡的操作非常复杂,内部的寄存器也不是一般的多。为了不过多占用主机的I/O空间,很多寄存器只能通过索引寄存器间接访问。
索引寄存器的端口号是0x3d4,可以向它写入一个值,用来指定内部的某个寄存器。比如,两个8位的光标寄存器,其索引值分别是14(0x0e)和15(0x0f),分别用于提供光标位置的高8位和低8位。
指定了寄存器之后,要对它进行读写,这可以通过数据端口0x3d5来进行。
中断和动态时钟显示¶
为了分享计算能力,处理器应当能够为多用户多任务提供硬件一级的支持。在单处理器的系统中,允许同时有多个程序在内存中等待处理器的执行。
当一个程序执行时,它是不会知道还有别的程序正眼巴巴地等着执行的。在这种情况下,就需要打断处理器当前的执行流程,去执行另外一些程序。执行完之后,还可以返回到原来的程序继续执行。
为了在需要的时候打断处理器当前的执行流程,去做另外的事情,执行别的代码,或者去执行另一个程序,中断(Interrupt)这种工作机制就应运而生了。
外部硬件中断¶
顾名思义,外部硬件中断,就是从处理器外面来的中断信号。当外部设备发生错误,或者有数据要传送(比如,从网络中接收到一个针对当前主机的数据包),或者处理器交给它的事情处理完了(比如,打印已经完成),又或者一个定时器到达指定的时间间隔时,它们都会拍一下处理器的肩膀,告诉它应当先把手头上的事情放一放,来临时处理一下。
如图下图所示,外部硬件中断是通过两个信号线引入处理器内部的。从很早的时候起,也就是8086处理器的时代,这两根线的名字就叫NMI和INTR。
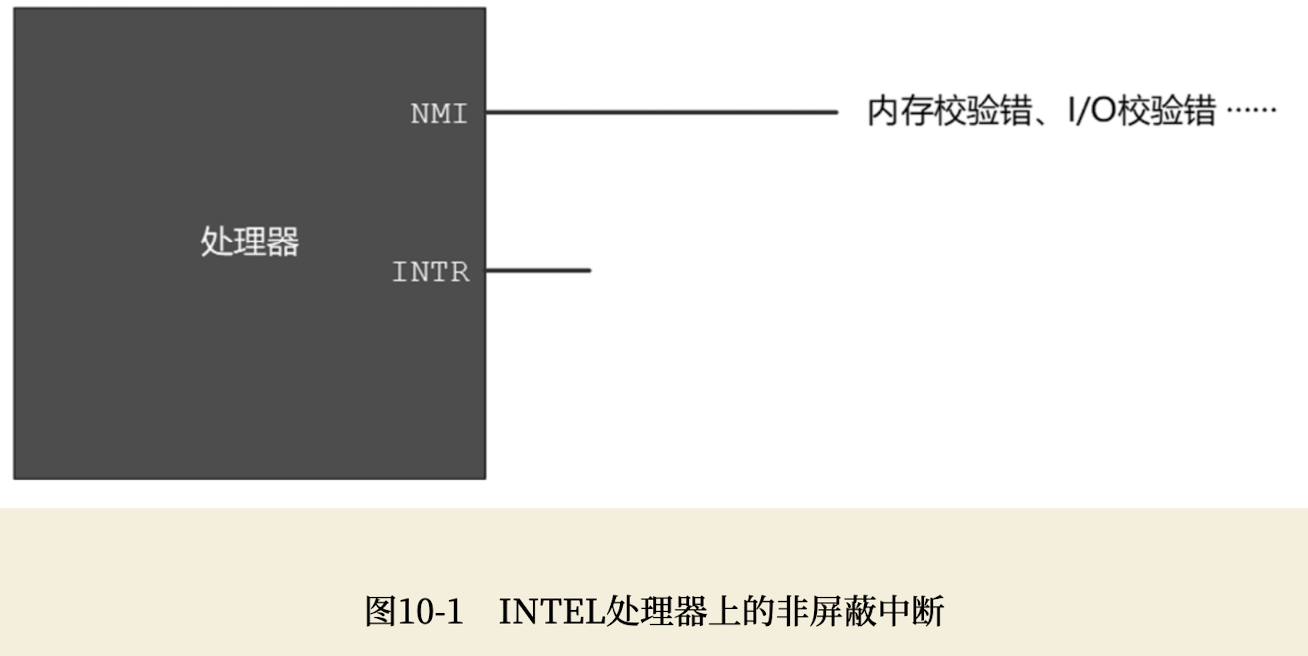
用两根信号线来接受外部设备的中断信号可能是多余的,也许只需要一根就可以了? 这似乎有些道理,但是,中断的原因很多,有些中断信号不是那么紧急,不用着急处理,或者,在处理器忙的时候,干脆就拒绝处理。
-
对于那些不紧急,不用着急处理的中断信号,应该从INTR引脚输入。在处理器内部,根据需要,可以屏蔽掉从这个引脚来的中断信号,不对它们进行处理。因此,从INTR输入的中断信号叫作可屏蔽中断。
-
所有严重事件都必须无条件地加以处理,由这类事件引发的中断信号应当通过NMI引脚送入处理器,这些严重的事件包括不间断电源的后备电池即将耗尽、内存校验错误、I/O检验错误,等等。在处理器内部,对于从NMI引脚来的中断信号不会作屏蔽和过滤,而是必须进行处理。因为这个原因,从NMI引脚来的中断信号称为 非屏蔽中断(Non Maskable Interrupt, NMI)。
非屏蔽中断¶
尽管非屏蔽中断在处理器内部是不可屏蔽的(这也是“非屏蔽中断”这个名称的由来),但是,在处理器外部却有一个开关来控制非屏蔽中断信号能否进入处理器。
INTEL处理器规定,NMI中断信号由0跳变到1后,至少要维持4个以上的时钟周期才算是有效的,才能被识别。
当一个中断发生时,处理器将会通过中断引脚NMI和INTR得到通知。除此之外,它还应当知道发生了什么事,以便采取适当的处理措施。每种类型的中断都被统一编号,这称为 中断类型号、中断向量或者 中断号。但是,由于不可屏蔽中断的特殊性——几乎所有触发NMI的事件对处理器来说都是致命的,甚至是不可纠正的。在这种情况下,努力去搞清楚发生了什么,通常没有太大的意义,这样的事最好留到关机之后,让专业维修人员来做。
也正是这个原因,在实模式下,NMI被赋予了统一的中断号2,不再进行细分。一旦发生2号中断,处理器和软件系统通常会放弃继续正常工作的“念头”,也不会试图纠正已经发生的问题和错误,很可能只是由软件系统给出一个提示信息。
可屏蔽中断¶
可屏蔽中断是通过INTR引脚进入处理器内部的。像NMI一样,不可能为每一个中断源都提供一个引脚,但与NMI不同的是,需要区分中断的类型和来源。在这种情况下,需要一个代理,来接受外部设备发出的中断信号。还有,多个设备同时发出中断请求的概率也是很高的,所以该代理的任务还包括对它们进行仲裁,以决定让它们中的哪一个优先向处理器提出服务请求。
如下图所示,在个人计算机中,最早使用的中断代理就是8259芯片,它就是通常所说的中断控制器,从8086处理器开始,它就一直提供着这种服务。即使是现在,在绝大多数单处理器的计算机中,也依然有它的存在。
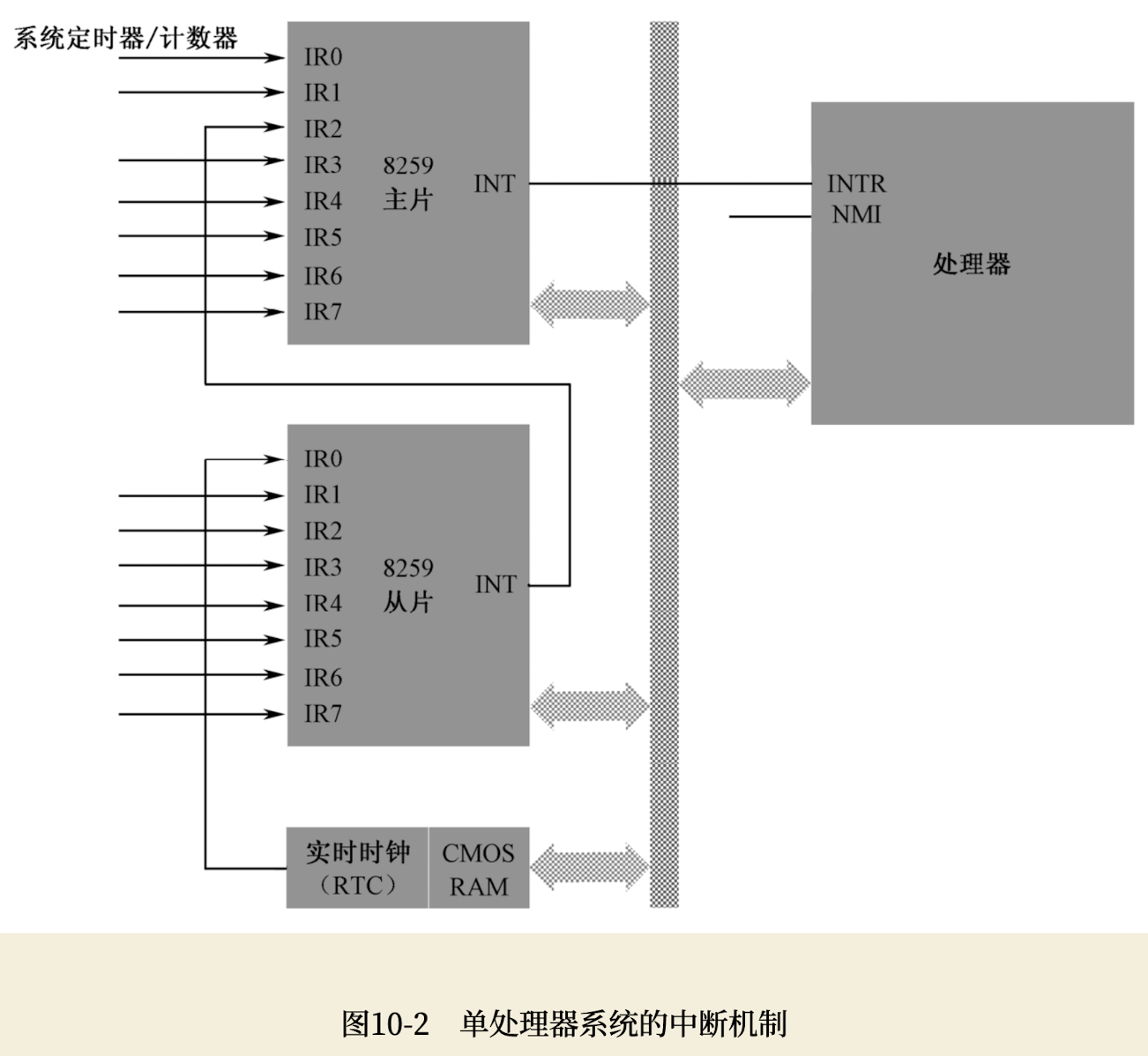
NTEL处理器允许256个中断,中断号的范围是0~255,8259负责提供其中的15个,但中断号并不固定。之所以不固定,是因为当初设计的时候,允许软件根据自己的需要灵活设置中断号,以防止发生冲突。该中断控制器芯片有自己的端口号,可以像访问其他外部设备一样用in和out指令来改变它的状态,包括各引脚的中断号。正是因为这样,它又叫 可编程中断控制器(Programmable Interrupt Controller, PIC)。
不知道是怎么想的,反正每片8259只有8个中断输入引脚,而在个人计算机上使用它,需要两块。如上图所示,第一块8259芯片的代理输出INT直接送到处理器的INTR引脚,这是主片(Master);第二块8259芯片的INT输出送到第一块的引脚2上,是从片(Slave),两块芯片之间形成级联(Cascade)关系。
如此一来,两块8259芯片可以向处理器提供15个中断信号。当时,接在8259上的15个设备都是相当重要的,如PS/2键盘和鼠标、串行口、并行口、软磁盘驱动器、IDE硬盘等。现在,这些设备很多都已淘汰或者正在淘汰中,根据需要,这些中断引脚可以被其他设备使用。
如上图所示,8259主片的引脚0(IR0)接的是系统定时器/计数器芯片;从片的引脚0(IR0)接的是实时时钟芯片RTC。总之,这两块芯片的固定连接即使是在硬件更新换代非常频繁的今天,也依然没有改变。
在8259芯片内部,有中断屏蔽寄存器(Interrupt Mask Register, IMR),这是个8位寄存器,对应着该芯片的8个中断输入引脚,对应的位是0还是1,决定了从该引脚来的中断信号是否能够通过8259送往处理器(0表示允许,1表示阻断,这可能出乎你的意料)。当外部设备通过某个引脚送来一个中断请求信号时,如果它没有被IMR阻断,那么,它可以被送往处理器。注意,8259芯片是可编程的,主片的端口号是0x20和0x21,从片的端口号是0xa0和0xa1,可以通过这些端口访问8259芯片,设置它的工作方式,包括IMR的内容。
中断能否被处理,除了要看8259芯片的脸色,最终的决定权在处理器手中。在处理器内部,标志寄存器有一个标志位IF,这就是中断标志(Interrupt Flag)。当IF为0时,所有从处理器INTR引脚来的中断信号都被忽略掉;当其为1时,处理器可以接受和响应中断。
IF标志位可以通过两条指令cli和sti来改变。这两条指令都没有操作数,cli(CLear Interrupt flag)用于清除IF标志位;sti(SeT Interrupt flag)用于置位IF标志。
中断信号的来源,或者说,产生中断的设备,称为 中断源。在计算机内部,中断发生得非常频繁,当一个中断正在处理时,其他中断也会陆续到来,甚至会有多个中断同时发生的情况,这都无法预料。不过不用担心,8259芯片会记住它们,并按一定的策略决定先为谁服务。总体上来说,中断的优先级和引脚是相关的,主片的IR0引脚优先级最高,IR7引脚优先级最低,从片也是如此。当然,还要考虑到从片是级联在主片的IR2引脚上的。
最后,当一个中断事件正在处理时,如果来了一个优先级更高的中断事件时,允许暂时中止当前的中断处理,先为优先级较高的中断事件服务,这称为 中断嵌套。
实模式下的中断向量表¶
所谓中断处理,归根结底就是处理器要执行一段与该中断有关的程序(指令)。处理器可以识别256个中断,那么理论上就需要256段程序。这些程序的位置并不重要,重要的是,在实模式下,处理器要求将它们的入口点集中存放到内存中从物理地址0x00000开始到0x003ff结束,共1KB的空间内,这就是所谓的 中断向量表(Interrupt Vector Table, IVT)。
如下图所示,每个中断在中断向量表中占2个字,分别是中断处理程序的偏移地址和逻辑段地址。中断0的入口点位于物理地址0x00000处,也就是逻辑地址0x0000:0x0000;中断1的入口点位于物理地址0x00004处,即逻辑地址0x0000:0x0004;其他中断依次类推,总之是按顺序的。
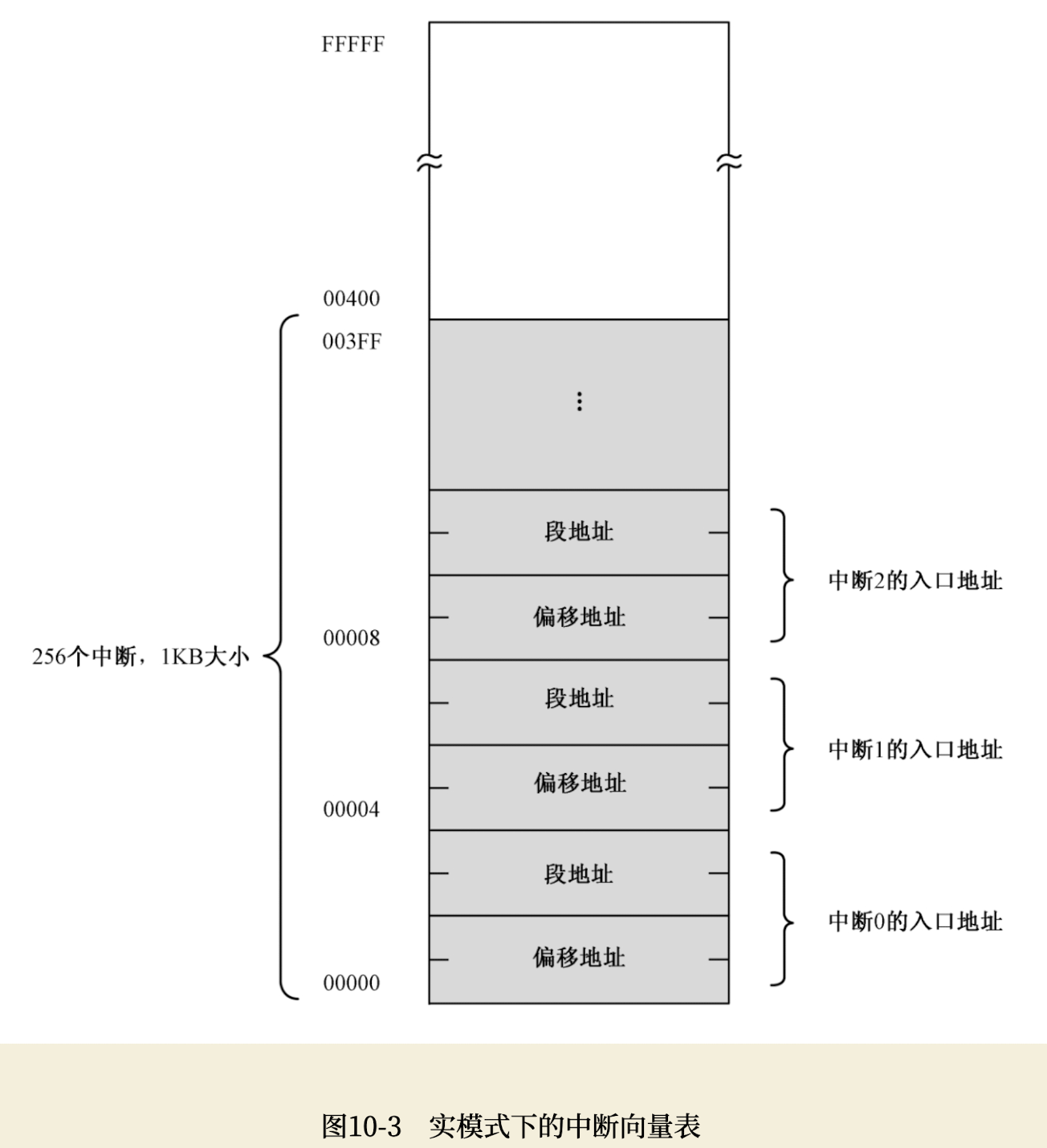
中断随时可能发生,中断向量表的建立和初始化工作是由BIOS在计算机启动时负责完成的。BIOS为每个中断号填写入口地址,因为它不知道多数中断处理程序的位置,所以,一律将它们指向一个相同的入口地址,在那里,只有一条指令:iret。也就是说,当这些中断发生时,只做一件事,那就是立即返回。当计算机启动后,操作系统和用户程序再根据自己的需要,来修改某些中断的入口地址,使它指向自己的代码。
实时时钟、CMOS RAM和BCD编码¶
也许你曾经觉得奇怪,为什么计算机能够准确地显示日期和时间?原因很简单,在外围设备控制器芯片ICH内部,集成了实时时钟电路(Real Time Clock, RTC)和两小块由互补金属氧化物(CMOS)材料组成的静态存储器(CMOS RAM)。实时时钟电路负责计时,而日期和时间的数值则存储在这块存储器中。
实时时钟是全天候跳动的,即使是在你关闭了计算机的电源之后,原因在于它由主板上的一个小电池提供能量。它为整台计算机提供一个基准时间,为所有需要时间的软件和硬件服务。不像8259芯片,有关RTC CMOS的资料相当少见,很不容易完整地找到,而8259的内容则铺天盖地,到处都是。
早期的计算机没有ICH芯片,各个接口单元都是分立的,单独地焊在主板上,并彼此连接。早期的RTC芯片是摩托罗拉(Motorola)MS146818B,现在直接集成在ICH内,并且在信号上与其兼容。除了日期和时间的保存功能,RTC芯片也可以提供闹钟和周期性的中断功能。
日期和时间信息是保存在CMOS RAM中的,通常有128字节,而日期和时间信息只占了一小部分容量,其他空间则用于保存整机的配置信息,比如各种硬件的类型和工作参数、开机密码和辅助存储设备的启动顺序等。这些参数的修改通常在BIOS SETUP开机程序中进行。要进入该程序,一般需要在开机时按DEL、ESC、F1、F2或者F10键。具体按哪个键,视计算机的厂家和品牌而定。
RTC芯片由一个振荡频率为32.768kHz的石英晶体振荡器(晶振)驱动,经分频后,用于对CMOS RAM进行每秒一次的时间刷新。
二进制编码的十进制数:BCD¶
要想说明什么是BCD(Binary Coded Decimal, BCD)编码,最好的办法是举个例子。比如十进制数25,其二进制形式是00011001。但是,如果采用BCD编码的话,则一字节的高4位和低4位分别独立地表示一个0到9之间的数字。因此,十进制数25对应的BCD编码是00100101。由此可以看出,因为十进制数里只有0~9,故用BCD编码的数,高4位和低4位都不允许大于1001,否则就是无效的。
实时时钟RTC的中断信号¶
实时时钟RTC电路可以产生三种中断信号,分别是:周期性中断(Periodic Interrupt, PF)、更新周期结束中断(Update-ended Interrupt, UI)和闹钟中断(Alarm Interrupt, AI)。
todo¶
- 进入Linux内核前的准备
- 进军保护模式
- zenglOX:开发自己的操作系统
- 品读 Linux 0.11 核心代码
- 内核启动过程:显示模式初始化和进入保护模式
- Roll your own toy UNIX-clone OS
- x86架构操作系统内核的实现